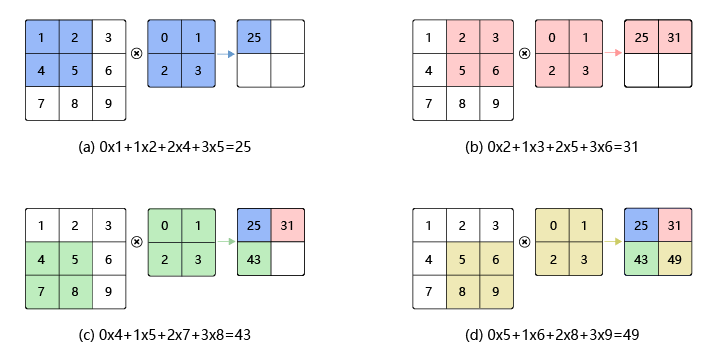
常用卷积总结
符号约定
输入:$H_{in} \times W_{in} \times C_{in}$,其中 $H_{in}$ 为输入 feature map的高,$W_{in}$ 为宽,$C_{in}$ 为通道数
输出:$H_{out} \times W_{out} \times C_{out}$,其中 $H_{out}$ 为输入 feature map的高,$W_{out}$ 为宽,$C_{out}$ 为通道数
卷积核:$N \times K \times K \times C_k$ ,其中 N 为该卷积层的卷积核个数,$K$ 为卷积核宽与高(默认相等),$C_k$ 为卷积核通道数
常规卷积特点:
卷积和通道数与输入 feature map的通道数相等,即 $C_{in} = C_k$
输出 feature map 的通道数等于卷积核的个数,即 $C_{out} = N$
卷积过程:
卷积核在输入 feature map 中移动,按位点乘后求和即可,通道也会求和。
函数语法格式,二维卷积最常用的卷积方式,先实例化再使用。
1nn. Conv2d(in_channels, out_c ...
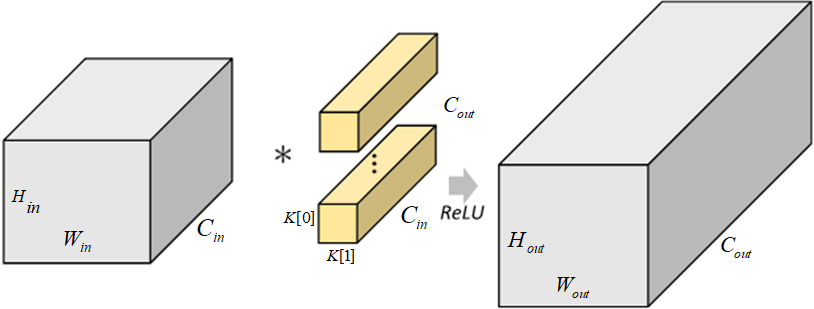
常见模块的参数量与计算量
计算量(FLOPs)和参数量(Parameters)
FLOPS(全大写):是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度,是一个衡量硬件性能的指标。
FLOPs(s小写):,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量,可以用来衡量算法/模型的复杂度,也就是我们这里要讨论的计算量。
参数定义(下同):$C_{int}$为输入通道数,k 为卷积核边长, $C_{out}$为输出通道数,$H_{out}*W_{out}$ 为输出特征图的长宽。
FLOPs = Paras $H_{out}W_{out}$ ;大致是这样的,参数量是和输入特征图大小无关的。
标准卷积层
Parameters:
考虑 bias:$(k^2C_{int}+1)C_{out}$
不考虑 bias:$(k^2C_{int})C_{out}$
FLOPs:
考虑 bias:$(2C_{int}k^2)C_{out}H_{out}*W_{out}$
不考虑 bias:$(2C_{ ...

常见代码实现
Softmax
计算公式:
Softmax(X)_{ij} = \frac{exp(X_{ij})}{\sum_{k}exp(X_{ij})}
计算过程:
对每个项求幂(使用exp;torch.exp())
对每一行(某一维度)求最大值,并且该行(维度)的值减去最大值,否则求exp(x)可能会溢出,导致inf的情况;
对每一行(某一维度)求和,得到每个样本的规范化常数。
将每一行除以其规范化常数,确保结果的和为1。
代码:
12345678910111213141516171819202122232425262728293031# numpydef softmax(x, axis=1): # 计算每行的最大值 # row_max = x.max(axis=axis) # row_max = np.expand_dims(row_max, axis=axis) row_max = np.max(x, axis=axis, keepdims=True) # 每行元素都需要减去对应的最大值,否则求exp(x)会溢出,导致inf情况 x = ...

图像处理算法总结
图像处理的简单总结
图像平滑:是通过降低图像中像素之间的变化来减少图像中的噪声和细节,使图像变得更加均匀和模糊。这在一些情况下很有用,如去除图像中的噪声、减少细节以改善压缩率或进行预处理以准备进行后续分析
图像锐化:增强图像的高频信息,增强图像的边缘和细节,使图像看起来更清晰和有深度。
图像腐蚀和膨胀:图像的膨胀和腐蚀是形态学的基本运算
图像腐蚀:腐蚀就是通过卷积核,将边界部分向内部靠近,逐步腐蚀掉。其目的是缩小图像中的对象,去除对象的小细节,以及分离靠得很近的对象。腐蚀操作也使用结构元素,但与对象像素相邻的条件下,输出图像中的相应位置只有在结构元素的中心与对象像素都相邻的情况下才设置为对象像素。
腐蚀操作会使对象变得更小,边界更加锐利,去除小的物体或细节。
图像膨胀:膨胀就是通过卷积核,将边界部分向外部靠近,逐步变粗。实际上膨胀就是腐蚀的逆过程。其目的是增加图像中对象的大小,填充对象的空隙,以及连接相邻的对象。它的工作原理是用一个称为结构元素的小矩形或圆形核对原始图像进行滑动运算。如果结构元素的中心与对象像素相邻,那么在输出图像中的相应位置就会设置为对象像素。
膨胀操作会使对 ...

机器学习相关算法总结
集成学习集成学习通过训练多个分类器,然后将其组合起来,从而达到更好的预测性能,提高分类器的泛化能力。
Baggging 和Boosting都是模型融合的方法,可以将弱分类器融合之后形成一个强分类器,而且融合之后的效果会比最好的弱分类器更好。
目前集成学习主要有三个主要框架:bagging,boosting,stacking。
偏差:训练到的模型与真实标签之间的区别。
方差:每次学习的模型之间差别有多大。
偏差指的是算法的期望预测与真实值之间的偏差程度,反映了模型本身的拟合能力;
方差度量了同等大小的训练集的变动导致学习性能的变化,刻画了数据扰动所导致的影响。
bagging套袋法bagging是并行集成学习方法的最著名代表,其算法过程如下:
从原始样本集中抽取训练集。每轮从原始样本集中使用Bootstraping的方法抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中)。共进行k轮抽取,得到k个训练集。(k个训练集之间是相互独立的)
每次使用一个训练集得到一个模型,k个训练集共得到k个模型。(注:这里并没有具体的分类算法或回归方法,我们可以根据具 ...
对比学习相关总结
Contrastive Learning对比学习的思想
对比学习的思想就是去拉近相似的样本,推开不相似的样本(在特征空间中拉近正样本之间的距离,推开负样本的距离)。而目标是要从样本中学习到一个较好的语义表示空间。
对比学习应该具备两个属性:Alignment 和 Uniformity
所谓“Alignment”,指的是相似的例子,也就是正例,映射到单位超球面后应该有接近的特征,也即是说,在超球面上距离比较近;
所谓“Uniformity”,指的是系统应该倾向在特征里保留尽可能多的信息,这等价于使得映射到单位超球面的特征,尽可能均匀地分布在球面上,分布得越均匀,意味着保留的信息越充分。分布均匀意味着两两有差异,也意味着各自保有独有信息,这代表信息保留充分
对比学习在loss设计时,为单正例多负例的形式,因为是无监督,数据是充足的,也就可以找到无穷的负例,但如何构造有效正例才是重点
对比学习的范式
对比学习的典型范式就是:代理任务+目标函数!代理任务和目标函数也是对比学习与有监督学习最大的区别。
对比学习之所以被认为是一种无监督的训练方式,是因为人们可以使用代理任务(pretext ...

Vision_Transformer相关总结
Transformer的小总结
Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V计算过程:$Q,K,V \in R^{B \times H \times W \times C}$ ==> 多头注意力$Q,K,V \in R^{B \times \times H \times W \times numHead \times C/numHead} ==>Q,k,V \in R^{B \times numHead \times HW \times C/numHead }$ ==> 注意力矩阵 $S = QK^T \in R^{B \times numHead \times HW \times HW}$==>提取value $SV \in R^{B \times numHead \times HW \times C/numhead} ==> R^{B \times HW \times C}$
Transformer简要介绍
Transfomer 是一种基于注意力机制的神经网络模型。Transformer模 ...

常见问题总结
深度学习基础常见问题总结神经网络中1*1卷积有什么作用?
降维,减少计算量;在ResNet模块中,先通过11卷积对通道数进行降通道,再送入33的卷积中,能够有效的减少神经网络的参数量和计算量;
升维;用最少的参数拓宽网络通道,通常在轻量级的网络中会用到,经过深度可分离卷积后,使用1*1卷积核增加通道的数量。
实现跨通道的交互和信息整合;增强通道层面上特征融合的信息,在feature map尺度不变的情况下,实现通道升维、降维操作其实就是通道间信息的线性组合变化,也就是通道的信息交互整合的过程;
增加非线性;1*1卷积核可以在保持feature map尺度(不损失分辨率)不变的情况下,大幅增加非线性特性(利用后接的非线性激活函数)。
卷积神经网络中用1*1 卷积有什么作用或者好处呢?
卷积后再次应用非线性
梯度消失和梯度爆炸的原因是什么?怎么解决?梯度消失和梯度爆炸问题都是因为网络太深,网络权值更新不稳定造成的,本质上是因为梯度反向传播中的连乘效应。
梯度消失和梯度爆炸的概念
根据损失函数计算的误差通过梯度反向传播的方式对深度网络权值进行更新时,得到的梯度值接近0或特别 ...
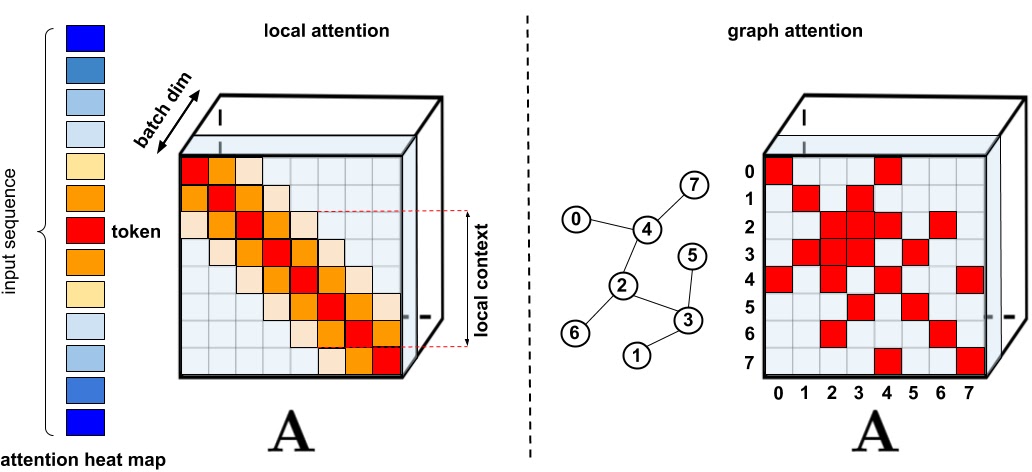
常用Attention总结
前沿什么是注意力机制?注意力机制是深度学习常用的一个小技巧,它有多种多样的实现形式,尽管实现方式多样,但是每一种注意力机制的实现的核心都是类似的,就是注意力。
注意力机制的核心重点就是让网络关注到它更需要关注的地方。
当我们使用卷积神经网络去处理图片的时候,我们会更希望卷积神经网络去注意应该注意的地方,而不是什么都关注,我们不可能手动去调节需要注意的地方,这个时候,如何让卷积神经网络去自适应的注意重要的物体变得极为重要。
注意力机制就是实现网络自适应注意的一个方式。
一般而言,注意力机制可以分为通道注意力机制(Channel-Attention),空间注意力机制(Spatial-Attention),以及二者的结合,自注意力(Self-Attention)。
SENet的实现(1)SENet是通道注意力的典型实现
(2)示意图如下所示,对于输入进来的特征层,我们关注每个通道的权重,对于SENet而言,其重点是获得输入进来的特征层,每个通道的权值。利用SENet,可以让网络关注它最需要关注的通道。
(3)具体实现:
1)对输入进来的特征层进行全局平均池化,通过pooling操作从而将通 ...
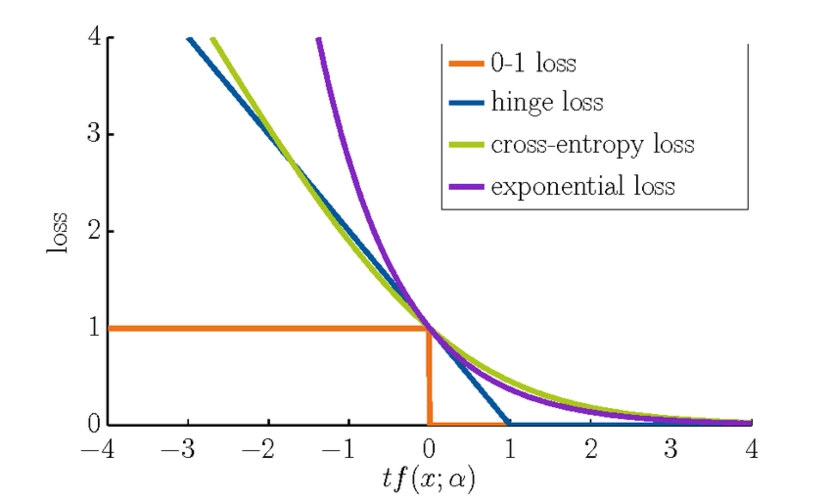
Loss_in_Deep_Learning
Loss in Deep Learning监督学习主要分为两类
回归问题:目标输出变量是连续结果,如预测西瓜的含糖率(0.00~1.00)
分类问题:目标输出变量是离散结果,如判断一个西瓜是好瓜还是坏瓜,那么目标变量只能是1(好瓜),0(坏瓜)
二分类问题:只有两个类别
多分类问题:多个类别。
损失函数严格上可分为两类:分类损失和回归损失,其中分类损失根据类别数量又可分为二分类损失和多分类损失。在使用的时候需要注意的是:回归函数预测数量,分类函数预测标签。
回归损失函数平均绝对误差损失(MAE)平均绝对误差 Mean Absolute Error(MAE) 是常用的损失函数,也称为 L1 Loss,其基本公式为:
L_{MAE} = \frac{1}{N} \sum_{i=1}^{N}\left | y_{i} - \hat{y}_i \right |简单说就是预测值和标签值差值的绝对值平均值,其可视化图如下图,MAE损失的最小值为0(当预测值等于真实值),最大值为无穷大,可以看出随着预测值与真实值绝对误差 $\left | y_{i} - \hat{y}_i \righ ...