Regularization_Summary
正则化总结欠拟合和过拟合
欠拟合是指模型不能在训练集上获得足够低的误差。
过拟合是指训练误差和测试误差之间的差距太大,神经网络对训练数据进行很好的建模但在看到来自同一问题域的新数据时失败的现象。
模型容量低,而训练数据复杂度高时,此时模型由于学习能力不足,无法学习到数据集中的“一般规律”,因而导致训练误差高,表现为欠拟合。
模型容量高,而训练数据简单时,此时模型由于学习能力太强,记住所有的训练数据,却没有理解数据背后的规律,对于训练集以外的数据泛化能力差,表现为过拟合。
解决欠拟合
在模型容量和训练数据复杂度不匹配时,发生了欠拟合现象,常见解决方法有:
增加新特征:可以考虑加入特征组合、高次特征等,来增大假设空间。
增大模型容量:容量低的模型可能很难拟合训练集。
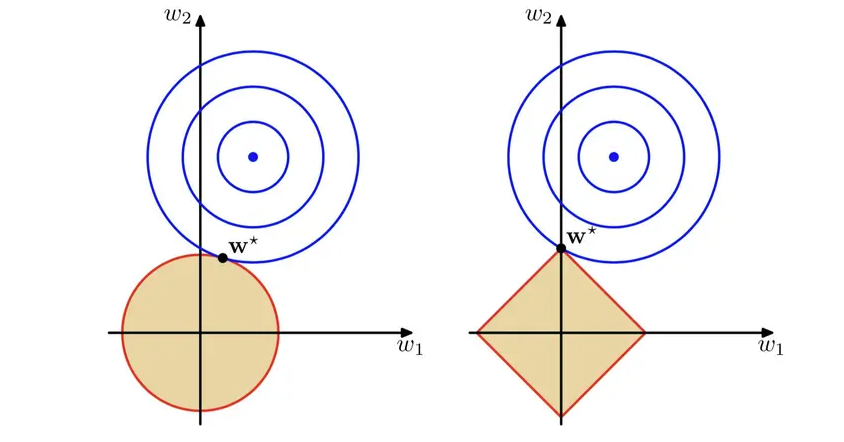
减少正则化参数:正则化的目的是用来防止过拟合的,但是模型出现了欠拟合,则需要减少正则化参数。
解决过拟合引起过拟合的主演原因如下:
训练数据集问题。如训练样本不均衡,训练集中正样本偏多,那么去预测负样本肯定不准;训练样本数据少,尤其是当比模型参数数量还少时,更容易发生过拟合;训练数据噪声干扰过大,模型会学习很多的噪 ...
Metric_in_Semantic_Segmentation
Metric in Semantic SegmentationDice Coefficient
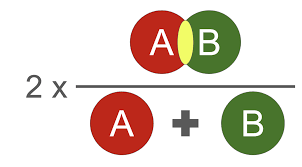
定义:Dice系数,是一种集合相似度度量函数,通常用于计算两个样本点的相似度(值范围为[0, 1])。用于分割问题,分割最好时为1,最差为0。(可解决样本不均衡问题)
计算公式:
Dice = \frac{2 \times \left | X \cap Y \right |}{\left | X \right | + \left | Y \right | } = \frac{2 \times 预测正确的结果 }{ 真实结果 + 预测结果 } \qquad\qquad X是标签;Y是预测值其中 $\left | X \cap Y \right |$ 是表示 X 和 Y 的交集(逐像素相乘后相加),$\left | X \right | $ 和 $ \left | Y \right |$ 表示其元素的个数(逐像素(Or平方)相加)。在计算的时候一般会加一个smooth,防止分母出现0
Dice loss = 1 - Dice
代码实现1(简单):
12345678 ...
Normalized_Summary
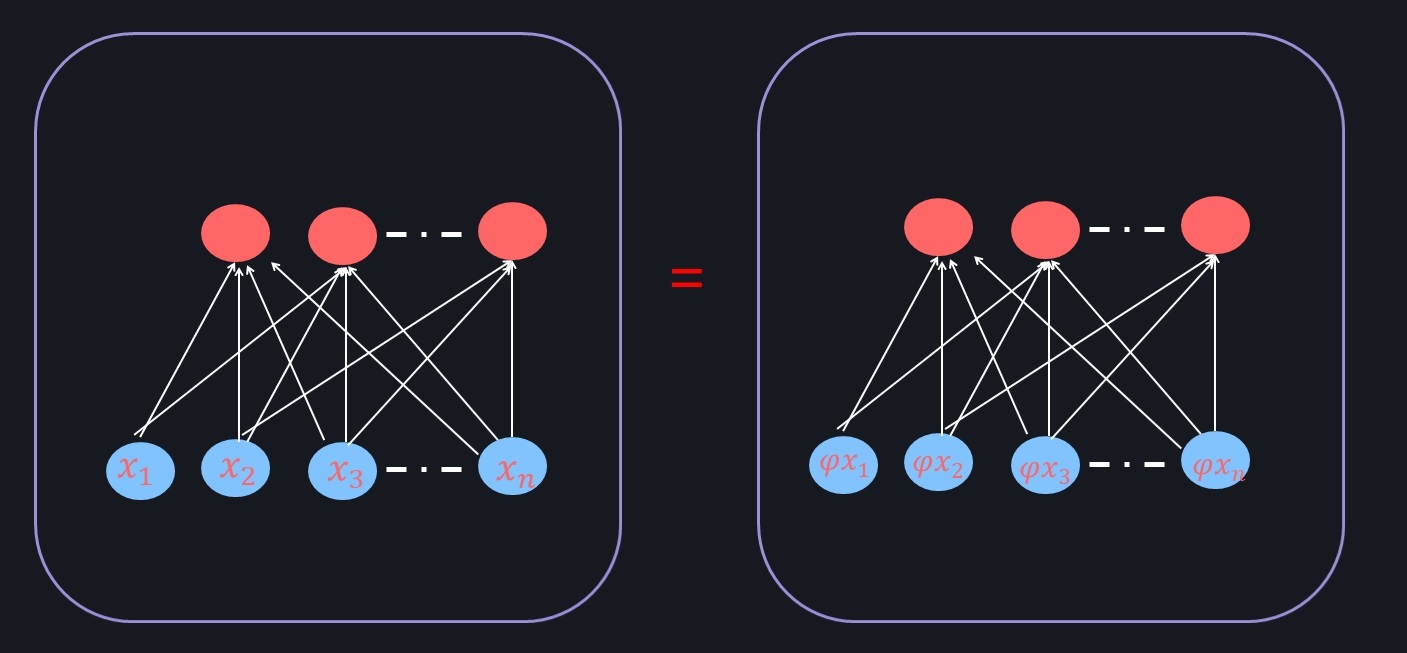
归一化总结(Normalization)神经网络的学习的本质就是学习数据的分布,使模型收敛,得到学习数据的特性。如果没有对数据进行归一化处理,那么每一批次训练的数据的分布就有可能不一样。从大的方面来讲,神经网络需要在多个分布中找到一个合适的平衡点;从小的方面来说,由于每层网络的输入数据在不断的变化,这会导致不容易找到合适的平衡点,最终使得构建的神经网络模型不容易收敛。当然,如果只是对输入数据做归一化,这样只能保证数据在输入层是一致的,并不能保证每层网络的输入数据分布是一致的,所以在神经网络模型的中间层也需要加入归一化处理。利用随机梯度下降更新参数时,每次参数更新都会导致网络中间每一层的输入的分布发生改变。越深的层,其输入分布会改变的越明显。
内部协变量偏移(Internal Covariate Shift):也就是在训练过程中,隐层的输入分布老是变来变去, 每一层的参数在更新过程中,会改变下一层输入的分布,神经网络层数越多,变现的越明显。为了解决内部协变量偏移问题,这就要使得每一个神经网络层的输入的分布在训练过程保持一致。
批量归一化(Batch Normalization, BN)为 ...

Data_Enhancemenct
Data Enhancement
数据增强可以提高泛化能力,但这一过程依赖于数据集,而且需要专门知识。其次,数据增强假定领域内样本都是同一类,且没有对不同类不同样本之间领域关系进行建模。
避免过拟合。当数据集具有某种明显的特征,例如数据集中图片基本在同一个场景中拍摄,使用Cutout方法和风格迁移变化等相关方法可避免模型学到跟目标无关的信息。
提升模型鲁棒性,降低模型对图像的敏感度。当训练数据都属于比较理想的状态,碰到一些特殊情况,如遮挡,亮度,模糊等情况容易识别错误,对训练数据加上噪声,掩码等方法可提升模型鲁棒性。
增加训练数据,提高模型泛化能力。
避免样本不均衡。在工业缺陷检测方面,医疗疾病识别方面,容易出现正负样本极度不平衡的情况,通过对少样本进行一些数据增强方法,降低样本不均衡比例
常规弱增强
随机缩放,随机按 [0.5, 2.0] 调整图像大小。
随机翻转,以 0.5 的概率水平翻转图像。
随机裁剪,从图像中随机裁剪一个区域(513 × 513,769 × 769)
常规强增强
Identity,返回原始图像。
反相,将图像像素反相。
自动对比度,最大化(正常化)图像 ...
SETR:Rethinking_Semantic_Segmentation_from_a_Sequence-to-Sequence_Perspective_with_Transformers
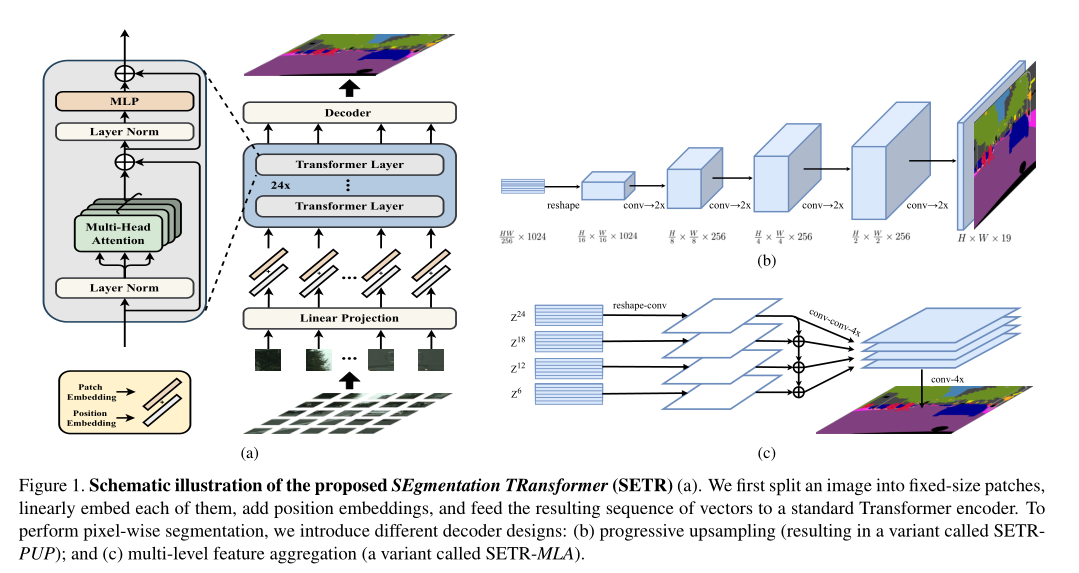
Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
代码:https://github.com/fudan-zvg/SETR
论文:https://arxiv.org/abs/2012.15840
introduction最新的语义分割方法采用具有编码器-解码器体系结构的全卷积网络(FCN)。编码器逐渐降低空间分辨率,并通过更大的感受野学习更多的抽象/语义视觉概念。由于上下文建模对于分割至关重要,因此最新的工作集中在通过扩张/空洞卷积或插入注意力模块来增加感受野。但是,基于编码器-解码器的FCN体系结构保持不变。
在本文中,我们旨在通过将语义分割视为序列到序列的预测任务来提供替代视角。具体来说,我们部署一个纯 transformer(即,不进行卷积和分辨率降低)将图像编码为一系列patch。通过在 transformer的每一层中建模全局上下文,此编码器可以与简单的解码器组合以提供功能强大的分割模型,称为SEgmentation TRansformer ...
TransFuse:Fusing_Transformers_and_CNNs_for_Medical_Image_Segmentation
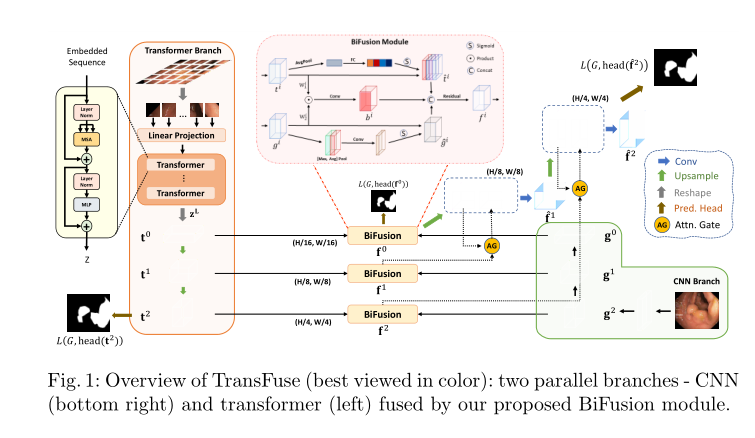
TransFuse: Fusing Transformers and CNNs for Medical Image Segmentation
代码:https://github.com/Rayicer/TransFuse
论文:https://arxiv.org/abs/2102.08005
introduction传统CNN网络很难捕获长距离的依赖关系,而且一味的加深网络的深度会带来大量的计算冗余。
文章提出了一种并行分支的TransFuse网络,结合transformer和CNN两种网络架构,能同时捕获全局依赖关系和低水平的空间细节,文中还提出了一种BiFusion module用来混合两个分支所提取的图像特征。使用TransFuse,可以以较浅的方式有效地捕获全局依赖性和low-level空间细节
transformer:good at modeling global context,but lack of spatial inductive-bias in modelling local information and limitations in capturing f ...

simpler-is-better:Few-shot_Semantic_Segmentation_with_Classifier_Weight_Transformer
Simpler is Better: Few-shot Semantic Segmentation with Classifier Weight Transformer
代码:https://github.com/zhiheLu/CWT-for-FSS
论文:https://arxiv.org/abs/2108.03032
introduction得益于大型的标签数据和深度学习算法的发展,语义分割方法近几年取得了很大的进步。但这些方法有两个局限:
1)过度依赖带标签数据,而这些数据的获得通常消耗大量人力物力;
2)训练好的模型并不能处理训练过程中未见的新类别。
面对这些局限,小样本语义分割被提出来,它的目的是通过对少量样本的学习来分割新类别。一般来说,小样本语义分割方法是通过用训练数据模拟测试环境进行元学习使得训练的模型有很好的泛化能力,从而在测试时可以仅仅利用几个样本的信息来迭代模型完成对新类别的分割。具体地,小样本分割模型是在大量的模拟任务上进行训练,每个模拟任务有两个数据组:Support set and Query set。Support set 是有标签的K-shot样本 ...

SOTR-Segmenting-Objects-with-Transformers
SOTR: Segmenting Objects with Transformers
代码:https://github.com/easton-cau/SOTR
论文:https://arxiv.org/abs/2108.06747
introduction
首先作者研究了实例分割的发展历程,以及各个阶段方法的大概总结,提出个各个阶段的优点与不足的,在实例分割这块,主要的方法就是包括
Top-down instance segmentation 和 Bottom-up instance segmentation
Top-down instance segmentation
proposal-based方法:基于目标检测,在得到目标检测框之后再在框内做语义分割分割前景背景,由于这种方法需要借助目标检测中的区域提议,因此该方法称为proposal-based方法.,这种方法就是遵循先检测后分割的范式的。缺点如下 例如 Mak-RCNN
1)由于有限的感受野,CNN在高级视觉语义信息中相对缺乏 特征的连贯性来关联实例 , 导致对大对象的次优结果;
2)分割质量和推理速度都严重依赖 ...

浅析UNet
前言研究一个深度学习算法,可以先看网络结构,看懂网络结构后,再Loss计算方法、训练方法等。本文主要针对UNet的网络结构进行讲解
卷积神经网络被大规模的应用在分类任务中,输出的结果是整个图像的类标签。但是UNet是像素级分类,输出的则是每个像素点的类别,且不同类别的像素会显示不同颜色,UNet常常用在生物医学图像上,而该任务中图片数据往往较少。所以,Ciresan等人训练了一个卷积神经网络,用滑动窗口提供像素的周围区域(patch)作为输入来预测每个像素的类标签。
优点
输出结果可以定位出目标类别的位置;
由于输入的训练数据是patches,这样就相当于进行了数据增强,从而解决了生物医学图像数量少的问题,数据增强有利于模型的训练
缺点
训练过程较慢,网络必须训练每个patches,由于每个patches具有较多的重叠部分,这样持续训练patches,就会导致相当多的图片特征被多次训练,造成资源的浪费,导致训练时间加长且效率会低下。但是也会认为网络对这个特征进行多次训练,会对这个特征影响十分深刻,从而准确率得到改进。但是这里你拿一张图片复制100次去训练,很可能会出现过拟合的现象 ...

计算机视觉的基本知识介绍
计算机视觉方向:图像分类,图像检测,目标检测,图像分割,图像生成,目标跟踪,超分辨率重构,关键点定位,图像降噪,多模态,图像加密,视频编解码,3D视觉等等
图像基本概念颜色空间
颜色空间也称彩色模型,用于描述色彩
常见的颜色空间包括:RGB(常用3通道)、CMYK、YUV(摄像头)
RGB色彩模式
RGB色彩模式是工业界的一种颜色标准
通过对红(R)、绿(G)、蓝(B)三个颜色通道的变化以及它们相互之间的叠加来得到各式各样的颜色的
红、绿、蓝三个颜色通道每种色各分为256阶亮度,(R,G,B)三维就是一个像素点,(0,0,0)黑,(255,255,255)白
H W C H:长,W:宽,C:通道
HSV色彩模式
色相(Hue):指物体传导或反射的波长。更常见的是以颜色如红色,橘色或绿色来辨识,取0到360度的数值来衡量
饱和度(Saturation):又称色度,是指色彩的强度或纯度,取值范围为0%~100%
明度(Value):表示颜色明亮的程度,取值范围为0%(黑)到100%(白)
灰度图
灰度图通常由一个unit8、unit16、单精度类型或者双精度类型的数组描述,也 ...