神经网络的来龙去脉
神经网络的来龙去脉
神经,名呼其曰,就是动物的神经系统,从外界的条件触感和感知到大脑中枢的控制再到控制神经做出一系列的反应。
其实,在人工只能领域的神经网络而言,大部分的神经网络都可以用深度 (depth),和连接结构(connection),但是具体的会具体说明。笼统的说,神经网络是可以分为有监督,无监督,半监督的神经网络,其实在这个分类下,忘忘也是你中有我我中有你的的一个局面,在学习的过程中有时候不必要去抠字眼。下面自己在浏览学习后,对神经网络的一点总结。
发展历程:
感知机 ==》多层感知机 ==》深度神经网络 ==》卷积神经网络
神经网络
神经网络即指人工神经网络,或称作连接模型,它是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。神经网络用到的算法是向量乘法,采用符号函数及其各种逼近。并行、容错、可以硬件实现以及自我学习特性,是神经网络的几个基本优点,也是神经网络计算方法与传统方法的区别所在。
神经网络发展
感知机
神经网络技术起源于上世纪五、六十年代,当时叫感知机(perceptron),拥有输入层、输出层和一个隐含层。输入的特征向量通过隐含层变换达到输出层,在输出层得到分类结果。早期感知机的推动者是Rosenblatt。但是,Rosenblatt的单层感知机有一个严重得不能再严重的问题,对于计算稍微复杂的函数其计算力显得无能为力。
多层感知机
随着数学的发展,这个缺点直到上世纪八十年代才被Rumelhart、Williams、Hinton、LeCun等人发明的多层感知机(multilayer perceptron)克服。多层感知机,顾名思义,就是有多个隐含层的感知机。
多层感知机可以摆脱早期离散传输函数的束缚,使用sigmoid或tanh等连续函数模拟神经元对激励的响应,在训练算法上则使用Werbos发明的反向传播BP算法。对,这就是我们现在所说的神经网络( NN)!多层感知机解决了之前无法模拟异或逻辑的缺陷,同时更多的层数也让网络更能够刻画现实世界中的复杂情形。多层感知机给我们带来的启示是,神经网络的层数直接决定了它对现实的刻画能力——利用每层更少的神经元拟合更加复杂的函数。
即便大牛们早就预料到神经网络需要变得更深,但是有一个梦魇总是萦绕左右。随着神经网络层数的加深,优化函数越来越容易陷入局部最优解,并且这个“陷阱”越来越偏离真正的全局最优。利用有限数据训练的深层网络,性能还不如较浅层网络。同时,另一个不可忽略的问题是随着网络层数增加,“梯度消失”现象更加严重。具体来说,我们常常使用 sigmoid 作为神经元的输入输出函数。对于幅度为1的信号,在BP反向传播梯度时,每传递一层,梯度衰减为原来的0.25。层数一多,梯度指数衰减后低层基本上接受不到有效的训练信号
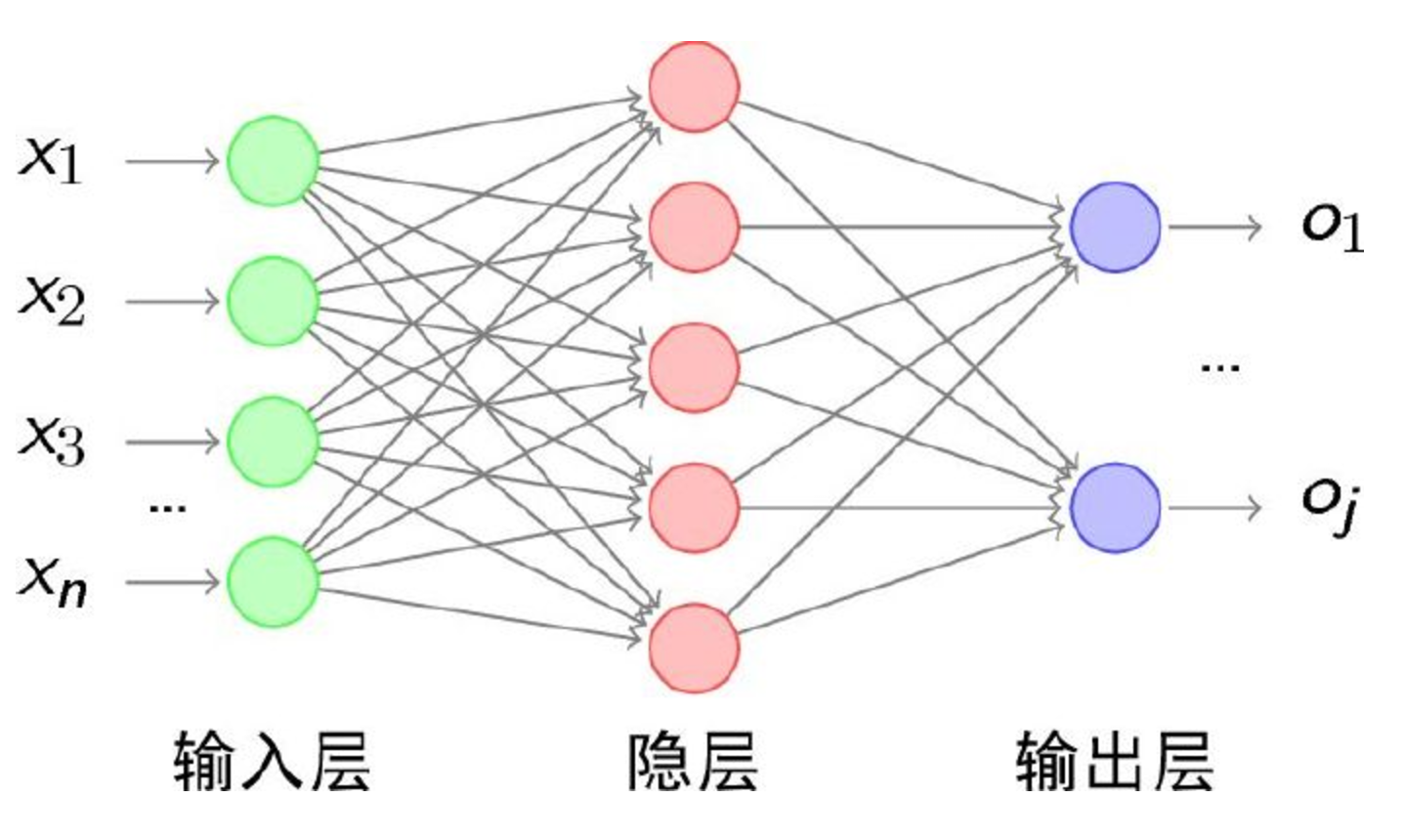
传统意义上的多层神经网络包含三层:
- 输入层
- 隐藏层
- 输出层
其中隐藏层的层数根据需要而定,没有明确的理论推导来说明到底多少层合适,多层神经网络做的步骤是:特征映射到值,特征是人工挑选。
深度神经网络 (DNN)
传统的人工神经网络(ANN)由三部分组成:输入层,隐藏层,输出层,这三部分各占一层。而深度神经网络的“深度”二字表示它的隐藏层大于2层,这使它有了更深的抽象和降维能力。
2006年,Hinton利用预训练方法缓解了局部最优解问题,将隐含层推动到了7层(参考论文:Hinton G E, Salakhutdinov R R. Reducing the Dimensionality of Data with Neural Networks[J]. Science, 2006, 313(5786):504-507.),神经网络真正意义上有了“深度”,由此揭开了深度学习的热潮。这里的“深度”并没有固定的定义——在语音识别中4层网络就能够被认为是“较深的”,而在图像识别中20层以上的网络屡见不鲜。为了克服梯度消失,ReLU、maxout等传输函数代替了 sigmoid,形成了如今 DNN 的基本形式。单从结构上来说,全连接的DNN和上图的多层感知机是没有任何区别的。值得一提的是,今年出现的高速公路网络(highway network)和深度残差学习(deep residual learning)进一步避免了梯度弥散问题,网络层数达到了前所未有的一百多层(深度残差学习:152层)
卷积神经网络(CNN)
如下图2所示,我们看到全连接DNN的结构里下层神经元和所有上层神经元都能够形成连接,带来的潜在问题是参数数量的膨胀。假设输入的是一幅像素为1K1K的图像,隐含层有1M个节点,光这一层就有10^12个权重需要训练,这不仅容易过拟合,而且极容易陷入局部最优。另外,图像中有固有的局部模式(比如轮廓、边界,人的眼睛、鼻子、嘴等)可以利用,显然应该将图像处理中的概念和神经网络技术相结合。此时我们可以祭出所说的卷积神经网络CNN。对于CNN来说,并不是所有上下层神经元都能直接相连,而是*通过“卷积核”作为中介。同一个卷积核在所有图像内是共享的,图像通过卷积操作后仍然保留原先的位置关系。
对于图像,如果没有卷积操作,学习的参数量是灾难级的。CNN之所以用于图像识别,正是由于CNN模型限制了参数的个数并挖掘了局部结构的这个特点。顺着同样的思路,利用语音语谱结构中的局部信息,CNN照样能应用在语音识别中。在普通的全连接网络或CNN中,每层神经元的信号只能向上一层传播,样本的处理在各个时刻独立,因此又被称为前向神经网络(Feed-forward Neural Networks)。
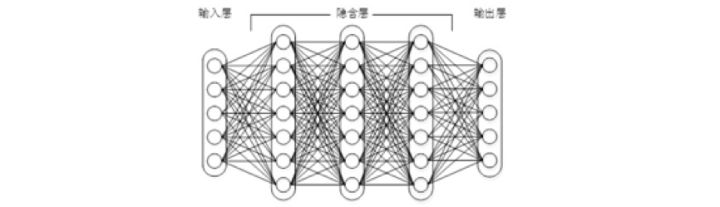
下面,通过一个例子简单说明卷积神经网络的结构。假设如下图3,m-l 是输入层,我们需要识别一幅彩色图像,这幅图像具有四个通道ARGB(透明度和红绿蓝,对应了四幅相同大小的图像),假设卷积核大小为100 100,共使用100个卷积核w1到w100(从直觉来看,每个卷积核应该学习到不同的结构特征)。用w1在ARGB图像上进行卷积操作,可以得到隐含层的第一幅图像;这幅隐含层图像左上角第一个像素是四幅输入图像左上角100100区域内像素的加权求和,以此类推。同理,算上其他卷积核,隐含层对应100幅“图像”。每幅图像对是对原始图像中不同特征的响应。按照这样的结构继续传递下去。CNN中还有max-pooling等操作进一步提高鲁棒性。
在这个例子里,我们注意到输入层到隐含层的参数瞬间降低到了100 100 100=10`6个!这使得我们能够用已有的训练数据得到良好的模型。题主所说的适用于图像识别,正是由于CNN模型限制参数了个数并挖掘了局部结构的这个特点。顺着同样的思路,利用语音语谱结构中的局部信息,CNN照样能应用在语音识别中。
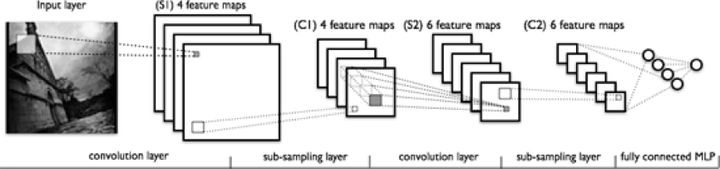
典型的卷积神经网络由3部分构成:
- 卷积层:负责提取图像中的局部特征
- 池化层:大幅降低参数量级(降维)
- 全连接层:类似传统神经网络的部分,用来输出想要的结果。
1)卷积:提取特征
卷积层的运算过程如下图,用一个卷积核扫完整张图片:
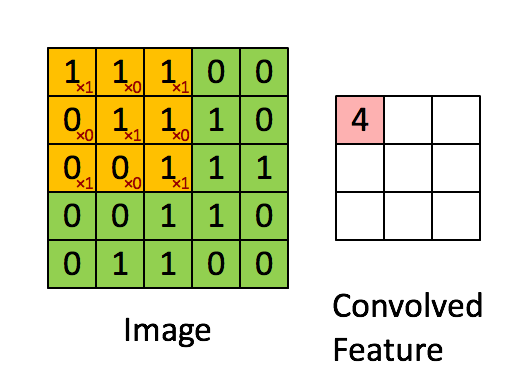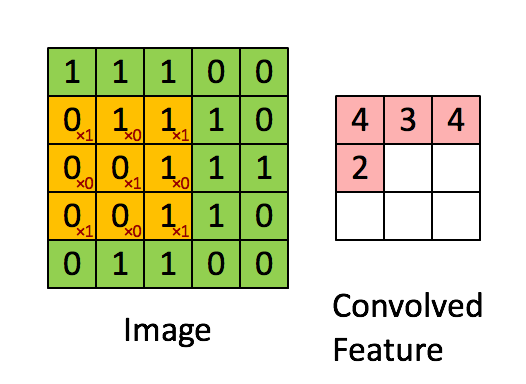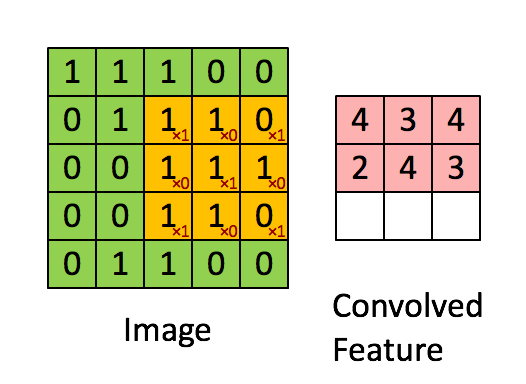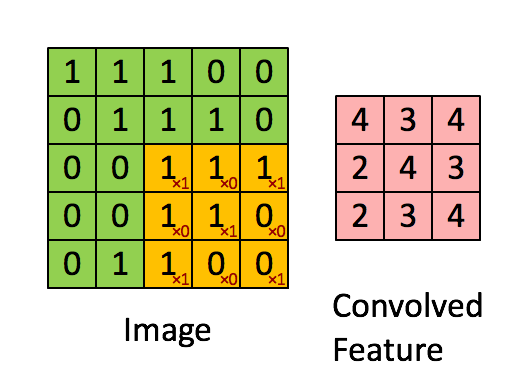
这个过程我们可以理解为我们使用一个过滤器(卷积核)来过滤图像的各个小区域,从而得到这些小区域的特征值。
在具体应用中,往往有多个卷积核,可以认为,每个卷积核代表了一种图像模式,如果某个图像块与此卷积核卷积出的值大,则认为此图像块十分接近于此卷积核。如果我们设计了6个卷积核,可以理解:我们认为这个图像上有6种底层纹理模式,也就是我们用6中基础模式就能描绘出一副图像。以下就是25种不同的卷积核的示例

总结:卷积层的通过卷积核的过滤提取出图片中局部的特征,跟上面提到的人类视觉的特征提取类似。
2)池化层(下采样):数据降维,避免过拟合
池化层简单说就是下采样,他可以大大降低数据的维度。其过程如下:
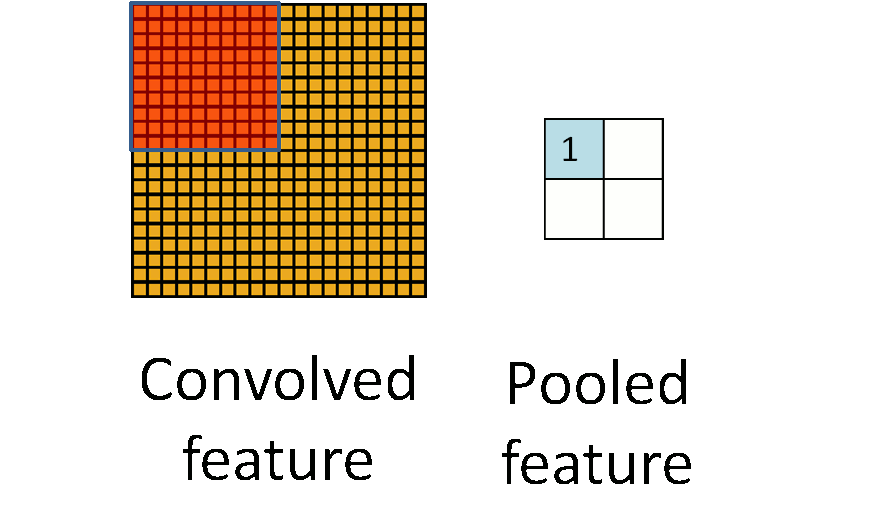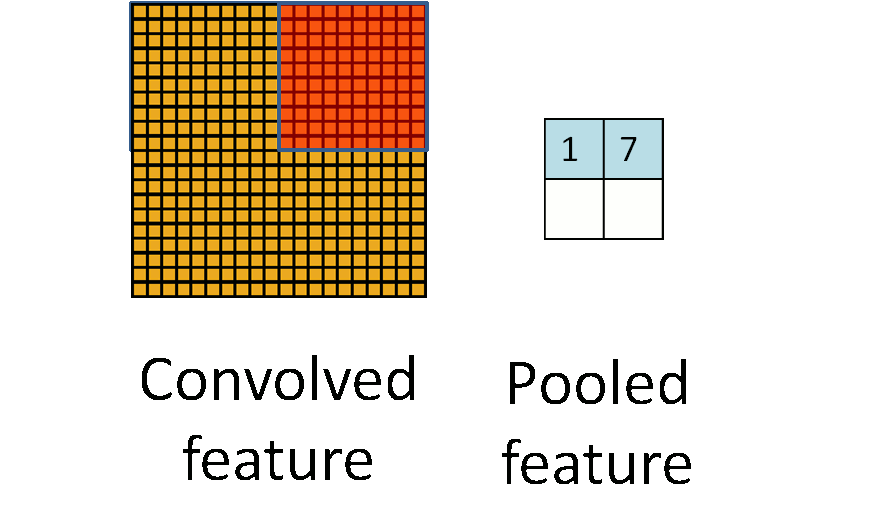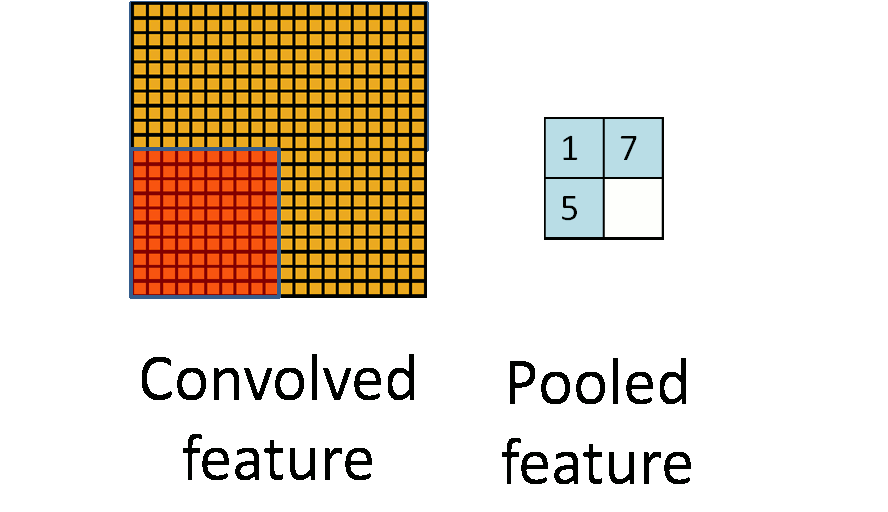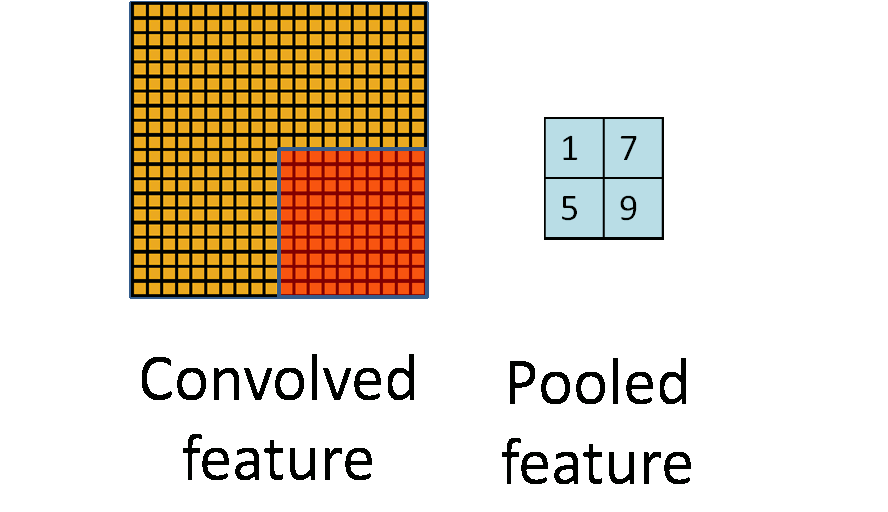
上图中,我们可以看到,原始图片是20×20的,我们对其进行下采样,采样窗口为10×10,最终将其下采样成为一个2×2大小的特征图。
之所以这么做的原因,是因为即使做完了卷积,图像仍然很大(因为卷积核比较小),所以为了降低数据维度,就进行下采样。
总结:池化层相比卷积层可以更有效的降低数据维度,这么做不但可以大大减少运算量,还可以有效的避免过拟合。
3)全连接层:输出结果
这个部分就是最后一步了,经过卷积层和池化层处理过的数据输入到全连接层,得到最终想要的结果。
经过卷积层和池化层降维过的数据,全连接层才能”跑得动”,不然数据量太大,计算成本高,效率低下。
典型的 CNN 并非只是上面提到的3层结构,而是多层结构,例如 LeNet-5 的结构就如下图所示:
卷积层 – 池化层- 卷积层 – 池化层 – 卷积层 – 全连接层

4)相关重点
1、卷积神经网络有2大特点
- 能够有效的将大数据量的图片降维成小数据量
- 能够有效的保留图片特征,符合图片处理的原则
2、卷积神经网络的擅长处理领域
卷积神经网络 – 卷积神经网络最擅长的就是图片的处理
3、卷积神经网络*解决了什么问题?*
在卷积神经网络出现之前,图像对于人工智能来说是一个难题,有2个原因:
- 图像需要处理的数据量太大,导致成本很高,效率很低
- 图像在数字化的过程中很难保留原有的特征,导致图像处理的准确率不高
A.需要处理的数据量太大
图像是由像素构成的,每个像素又是由颜色构成的。现在随随便便一张图片都是 1000×1000 像素以上的, 每个像素都有RGB 3个参数来表示颜色信息。假如我们处理一张 1000×1000 像素的图片,我们就需要处理3百万个参数!
1000×1000×3=3,000,000
这么大量的数据处理起来是非常消耗资源的,而且这只是一张不算太大的图片!
卷积神经网络 – CNN 解决的第一个问题就是「将复杂问题简化」,把大量参数降维成少量参数,再做处理。
更重要的是:我们在大部分场景下,降维并不会影响结果。比如1000像素的图片缩小成200像素,并不影响肉眼认出来图片中是一只猫还是一只狗,机器也是如此。
B.保留图像特征
假如一张图像中有圆形是1,没有圆形是0,那么圆形的位置不同就会产生完全不同的数据表达。但是从视觉的角度来看,图像的内容(本质)并没有发生变化,只是位置发生了变化。
所以当我们移动图像中的物体,用传统的方式的得出来的参数会差异很大!这是不符合图像处理的要求的。
而 CNN 解决了这个问题,他用类似视觉的方式保留了图像的特征,当图像做翻转,旋转或者变换位置时,它也能有效的识别出来是类似的图像。
循环神经网络(RNN)
全连接的DNN还存在着另一个问题——无法对时间序列上的变化进行建模。然而,样本出现的时间顺序对于自然语言处理、语音识别、手写体识别等应用非常重要。对了适应这种需求,就出现了题主所说的另一种神经网络结构——循环神经网络RNN。
在普通的全连接网络或CNN中,每层神经元的信号只能向上一层传播,样本的处理在各个时刻独立,因此又被成为前向神经网络(Feed-forward Neural Networks)。而在RNN中,神经元的输出可以在下一个时间戳直接作用到自身,即第层神经元在m时刻的输入,除了(i-1)层神经元在该时刻的输出外,还包括其自身在(m-1)时刻的输出!表示成图就是这样的
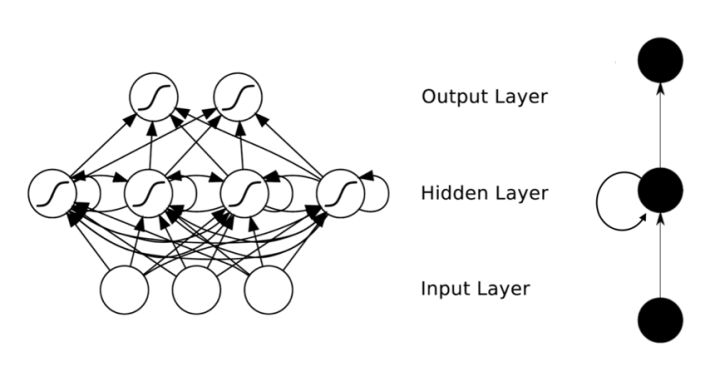
我们可以看到在隐含层节点之间增加了互连。为了分析方便,我们常将RNN在时间上进行展开,得到如图6所示的结构:
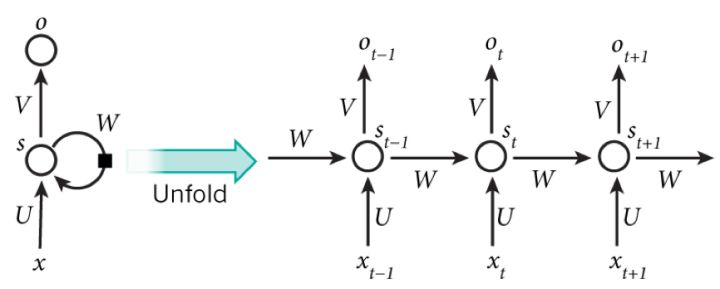
完美,(t+1)时刻网络的最终结果O(t+1)是该时刻输入和所有历史共同作用的结果!这就达到了对时间序列建模的目的。
不知题主是否发现,RNN可以看成一个在时间上传递的神经网络,它的深度是时间的长度!正如我们上面所说,“梯度消失”现象又要出现了,只不过这次发生在时间轴上。对于 t 时刻来说,它产生的梯度在时间轴上向历史传播几层之后就消失了,根本就无法影响太遥远的过去。因此,之前说“所有历史”共同作用只是理想的情况,在实际中,这种影响也就只能维持若干个时间戳。
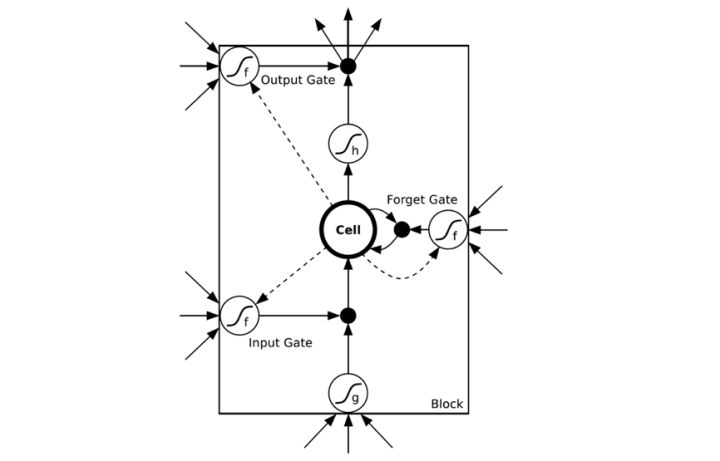
为了解决时间上的梯度消失,机器学习领域发展出了长短时记忆单元LSTM,通过门的开关实现时间上记忆功能,并防止梯度消失,一个LSTM单元长这个样子: