计算机视觉的基本知识介绍
计算机视觉方向:图像分类,图像检测,目标检测,图像分割,图像生成,目标跟踪,超分辨率重构,关键点定位,图像降噪,多模态,图像加密,视频编解码,3D视觉等等
图像基本概念
颜色空间
- 颜色空间也称彩色模型,用于描述色彩
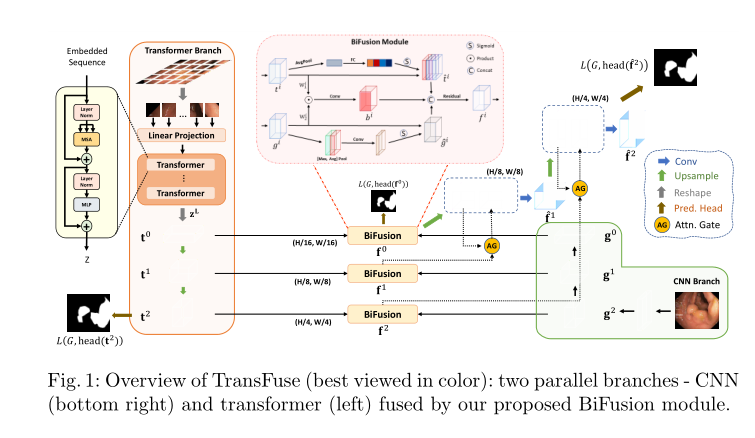
- 常见的颜色空间包括:RGB(常用3通道)、CMYK、YUV(摄像头)
RGB色彩模式
- RGB色彩模式是工业界的一种颜色标准
- 通过对红(R)、绿(G)、蓝(B)三个颜色通道的变化以及它们相互之间的叠加来
得到各式各样的颜色的 - 红、绿、蓝三个颜色通道每种色各分为256阶亮度,(R,G,B)三维就是一个像素点,(0,0,0)黑,(255,255,255)白
- H W C H:长,W:宽,C:通道
HSV色彩模式
- 色相(Hue):指物体传导或反射的波长。更常见的是以颜色如红色,橘色或绿色来辨识,取0到360度的数值来衡量
- 饱和度(Saturation):又称色度,是指色彩的强度或纯度,取值范围为0%~100%
- 明度(Value):表示颜色明亮的程度,取值范围为0%(黑)到100%(白)
灰度图
灰度图通常由一个unit8、unit16、单精度类型或者双精度类型的数组描述,也就是上面的 C=1,通道为 1
M*N的矩阵,矩阵中每一个元素与图像的一个像素点相对应
通常0代表黑色,1、255或65635(为数据矩阵的取值范围上限)代表白色
浮点算法:Gray=R0.3+G0.59+B0.11
整数方法:Gray=(R30+G59+B11)/100
移位方法:Gray=(R28+G151+B*77)>>8
平均值法:Gray=(R+G+B)/3
仅取绿色:Gray=G
图像处理基本概念
亮度,对比度,饱和度
- 亮度:图像的明亮程度,在单色图像中,最高的值应该对应于白色,最低的值应当对应于黑色;
- 对比度:图像暗和亮的落差值,即图像最大灰度级和最小灰度级之间的差值,差异范围越大代表对比越大,差异范围越小代表对比越小
- 饱和度:图像颜色种类的多少,饱和度越高,颜色种类越多,外观上看起来图像会更鲜艳
- 对于亮度和对比度,可以从RGB图上进行数据增强
- 对于饱和度,可以从HSV/HSI/HSL色彩空间上进行增强
图像平滑/降噪
- 图像平滑是指用于突出图像的宽大区域、低频成分、主干部分或抑制图像噪声和干扰高频成分的图像处理方法,使图像亮度平缓渐变,减小突变梯度,改善图像质量。会出现边缘没有,轮廓结构不明显了
- 归一化块滤波器(Normalized Box Filter)
- 高斯滤波器(Gaussian Filter)
- 中值滤波器(Median Filter)
- 双边滤波(Bilateral Filter)

图像锐化/增强
- 图像锐化与图像平滑是相反的操作,锐化是通过增强高频分量来减少图像中的模糊,增强图像细节边缘和轮廓,增强灰度反差,便于后期对目标的识别和处理。
- 锐化处理在增强图像边缘的同时也增加了图像的噪声。
- 方法包括:微分法和高通滤波法

边缘提取算子
图像中的高频和低频的概念理解、
通过微分的方式计算图像的边缘(色差或者灰度值做差)
Roberts算子
Prewitt算子
sobel算子
Canny算子
Laplacian算子
等等
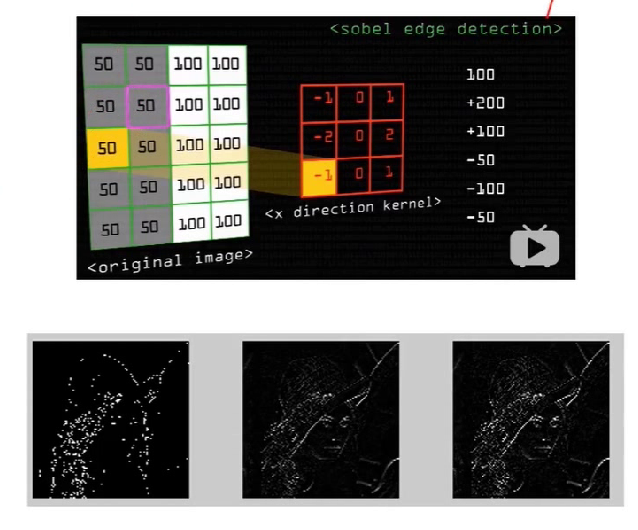
直方图均衡化
- 直方图均衡化是将原图像通过某种变换,得到一幅灰度直方图为均匀分布的新图像的方法。
- 对在图像中像素个数多的灰度级进行展宽,而对像素个数少的灰度级进行缩减,从而达到清晰图像的目的。
图像滤波
图像滤波可以更改或者增强图像。
通过滤波,可以强调一些特征或者去除图像中一些不需要的部分。
滤波是一个邻域操作算子,利用给定像素周围的像素的值决定此像素的最终的输出值
常见的应用包括去噪、图像增强、检测边缘、检测角点、模板匹配等
均值滤波
中值滤波
高斯滤波
双边滤波
等等
形态学运算
- 腐蚀:腐蚀的效果是把图片”变瘦”,其原理是在原图的小区域内取局部最小值。
- 膨胀:膨胀与腐蚀相反,取的是局部最大值,效果是把图片”变胖”
- 开运算:先腐蚀后膨胀(因为先腐蚀会分开物体,这样容易记住),可以分离物体,消除小区域
- 闭运算:先膨胀后腐蚀(先膨胀会使白色的部分扩张,以至于消除/“闭合”物体里面的小黑洞)
- 形态学梯度:膨胀图减去腐蚀图,得到轮廓图
- 顶帽:原图减去开运算后的图
- 黑帽:闭运算后的图减去原图

卷积神经网络概念介绍
由卷积核构建,卷积核简称为卷积,也称为滤波器。卷积的大小可以在实际需要时自定义其长和宽(1 1, 3 3, 5 * 5)。
卷积神经网:以卷积层为主的深度网络结构
- 卷积层,激活层,BN层,池化层,全连接层(FC层),损失层
卷积层定义
- 对图像和滤波矩阵做内积(逐个元素相乘再求和)的操作
- nn.Conv2d(in channels,out channels,kernel_size,stride=1,padding=0,dilation=1,groups=1,bias=True)

常见的卷积操作
- 分组卷积(group参数)
- 空洞卷积(dilation参数)
- 深度可分离卷积(分组卷积+1×1卷积)。
- 反卷积(torch.nn.ConvTranspose2d)
- 可变形卷积等等
理解卷积层的重要概念
感受野(Receptive Field),指的是神经网络中神经元“看到的”输入区域,在卷积神经网络中,feature map上某个元素的计算受输入图像上某个区域的影响,这个区域即该元素的感受野。
参数量:参与计算参数的个数,占用内存空间
FLOPS:每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
FLOPs:浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
MAC:乘加次数,用来衡量计算量。
从感受野不变+减少参数量的角度压缩卷积层,压缩卷积层参数&&计算量
采用多个3×3卷积核代替大卷积核
采用深度可分离卷积
通道Shuffle
Pooling层
Stride=2
等等常见卷积层组合结构:堆叠,跳连,并连
池化层(下采样)
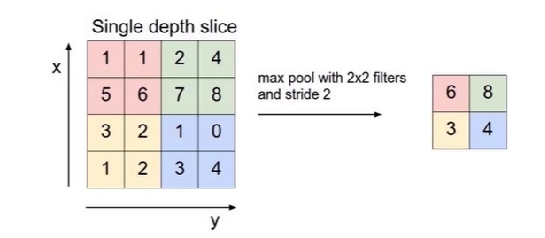
对图片进行压缩(降采样)的一种方法,如max pooling, average pooling等
对输入的特征图进行压缩
- 一方面使特征图变小,简化网络计算复杂度;
- 一方面进行特征压缩,提取主要特征
- 最大池化(Max Pooling)、平均池化(Average Pooling)等口
- nn.MaxPool2d(kernel_size,stride=None,padding=0,dilation=1,return_indices=False,ceil_mode=False)
上采样层
- Resize,如双线性插值直接缩放,类似于图像缩放,概念可见最邻近插值算法和双线性插值算法——图像缩放
- Deconvolution,也叫Transposed Convolution
- 实现函数
- nn.functi onal.interpolate(input,size=None,scale_factor=None,mode=’nearest’,align_corners=None)
- nn.ConvTranspose2d(in channels,out channels,kernel_size,stride=1,padding=0,output padding=0,bias=True)
激活层
激活函数的作用就是,在所有的隐藏层之间添加一个激活函数,这样的输出就是一个非线性函数了,因而神经网络的表达能力更加强大了。
激活函数:为了增加网络的非线性,进而提升网络的表达能力,详细见另外一篇博客
- ReLU函数、Leakly ReLU函数、ELU函数等
- torch.nn.ReLU(inplace=True)
BatchNorm层
- 通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布
- Batchnorm是归一化的一种手段,它会减小图像之间的绝对差异,突出相对差异,加快训练速度
- 不适用的问题:image-to-image以及对噪声敏感的任务
- nn.BatchNorm2d(num features,eps=1e-05,momentum=0.1,affine=True,track running_stats=True)
全连接层
口连接所有的特征,将输出值送给分类器(如softmax分类器)(线性)
- 对前层的特征进行一个加权和,(卷积层是将数据输入映射到隐层特征空间)将特征空间通过线性变换映射到样本标记空间(也就是label)
- 可以通过1×1卷积+global average pooling代替
- 可以通过全连接层参数冗余
- 全连接层参数和尺寸相关
nn.Linear(in features,out features,bias)
Dropout层
- 在不同的训练过程中随机扔掉一部分神经元
- 测试过程中不使用随机失活,所有的神经元都激活
- 为了防止或减轻过拟合而使用的函数,它一般用在全连接层
- nn.dropout
损失层
损失函数:在深度学习中,损失反映模型最后预测结果与实际真值之间的差距,可以用来分析训练过程的好坏、模型是否收敛等,例如均方损失、交叉熵损失等。
损失层:设置一个损失函数用来比较网络的输出和目标值,通过最小化损失来驱动网络的训练
网络的损失通过前向操作计算,网络参数相对于损失函数的梯度则通过反向操作计算
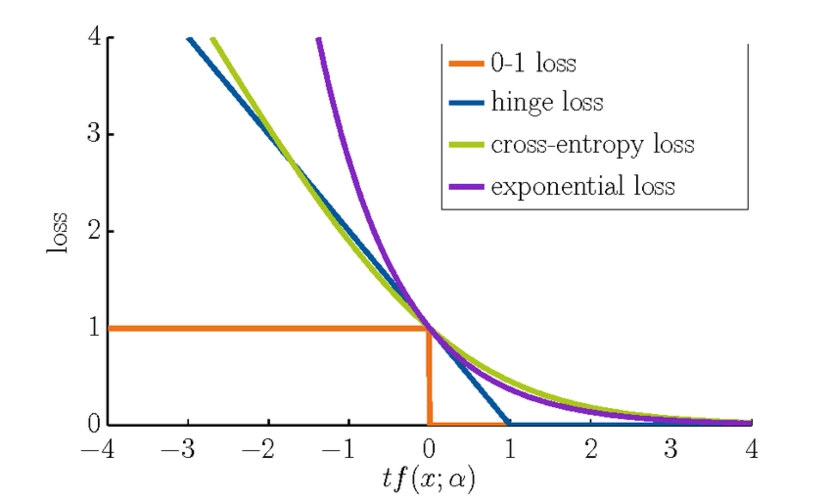
分类问题损失(分类分割)
- nn.BCELoss;nn.CrossEntropyLoss等等
回归问题损失(推测,回归)
- nn.L1Loss;nn.MSELoss;nn.SmoothL1Loss等等
经典卷积神经网络结构
堆叠,跳连,并连 ,轻量型网络结构,多分支网络结构,attention网络结构
其他重要概念
学习率
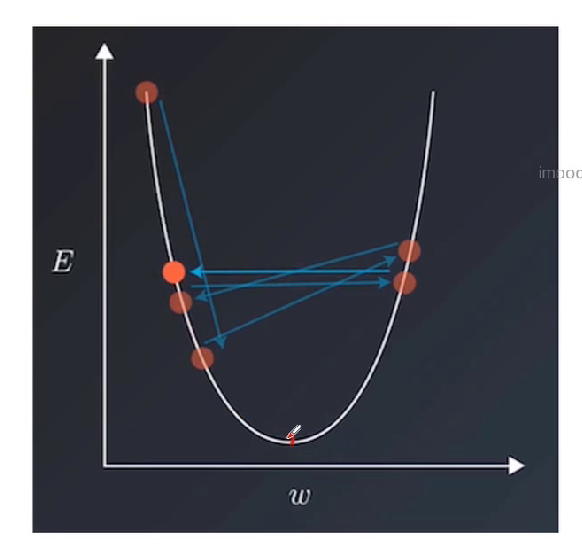
学习率作为监督学习以及深度学习中重要的超参,其决定着目标函数能否收敛到局部最小值以及何时收敛到最小值。
合适的学习率能够使目标函数在合适的时间内收敛到局部最小值
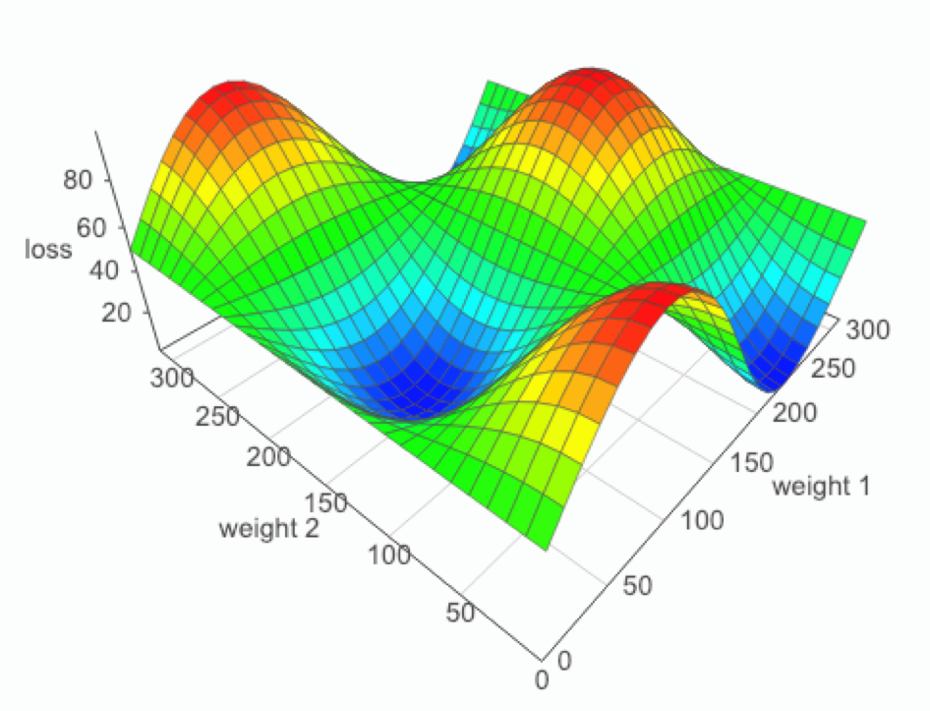
学习率大,震荡,恐怕到达不了最佳收敛值,学习率小收敛缓慢,消耗时间(如下图到最低点,学习率大小可以看作步长)
torch.optim.Ir scheduler
ExponentialLR
ReduceLROnPlateau
CyclicLR
等等
优化器
反向传播优化参数
- GD、BGD、SGD、MBGD
- 引入了随机性和噪声
- Momentum、NAG等
- 加入动量原则,具有加速梯度下降的作用
- AdaGrad,RMSProp,Adam、AdaDelta
- 自适应学习率
- torch.optim.Adam
正则化
模型出现过拟合现象时,降低模型复杂度
L1正则:参数绝对值的和
- L2正则:参数的平方和(Pytorch自带,weight decay)
- optimizer=torch.optim.SGD(model.parameters),Ir=0.01,weight_decay=0.001)
名词解释
参数与超参数
参数:模型f(x, θ)中的θ 称为模型的参数,可以通过优化算法进行学习。
超参数:用来定义模型结构或优化策略。
batch_size 批处理
- 每次处理的数据数量。
epoch 轮次
- 把一个数据集,循环运行几轮。
transforms 变换
- 主要是将图片转换为tensor,旋转图片,以及正则化。
nomalize 正则化
- 模型出现过拟合现象时,降低模型复杂度
前向传播
反向传播
梯度下降