对比学习相关总结
Contrastive Learning
对比学习的思想
对比学习的思想就是去拉近相似的样本,推开不相似的样本(在特征空间中拉近正样本之间的距离,推开负样本的距离)。而目标是要从样本中学习到一个较好的语义表示空间。
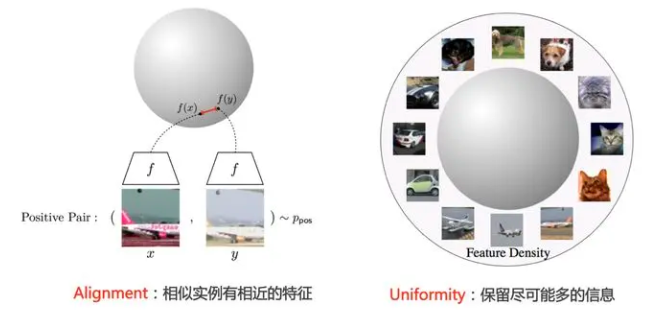
对比学习应该具备两个属性:Alignment 和 Uniformity
所谓“Alignment”,指的是相似的例子,也就是正例,映射到单位超球面后应该有接近的特征,也即是说,在超球面上距离比较近;
所谓“Uniformity”,指的是系统应该倾向在特征里保留尽可能多的信息,这等价于使得映射到单位超球面的特征,尽可能均匀地分布在球面上,分布得越均匀,意味着保留的信息越充分。分布均匀意味着两两有差异,也意味着各自保有独有信息,这代表信息保留充分
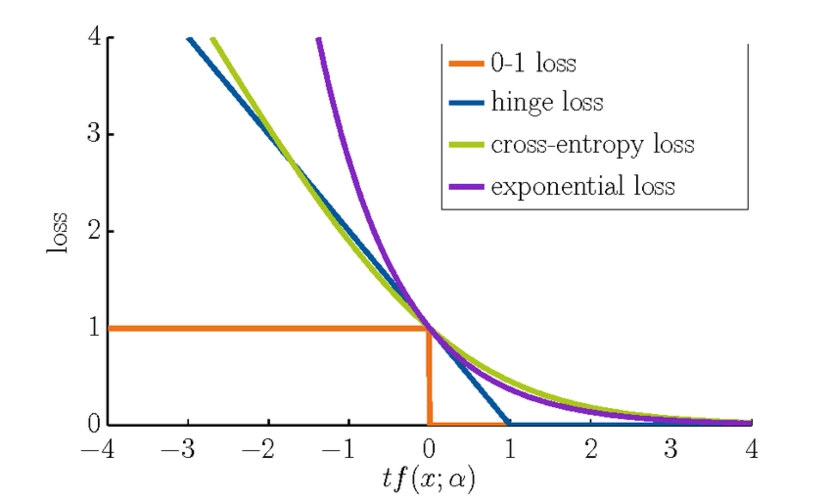
对比学习在loss设计时,为单正例多负例的形式,因为是无监督,数据是充足的,也就可以找到无穷的负例,但如何构造有效正例才是重点
对比学习的范式
对比学习的典型范式就是:代理任务+目标函数!代理任务和目标函数也是对比学习与有监督学习最大的区别。
对比学习之所以被认为是一种无监督的训练方式,是因为人们可以使用代理任务(pretext task)来定义谁与谁相似,谁与谁不相似,代理任务通常是人为设定的一些规则,这些规则定义了哪张图与哪张图相似,哪张图与哪张图不相似,从而提供了一个监督信号去训练模型,这就是所谓的自监督。对比学习可以叫自监督也可以叫无监督。数据增强是代理任务的实现常见手段。代理任务就是来解决无监督学习中没有ground-truth问题,我们用代理任务来定义对比学习的正负样本,无监督学习一旦有了输出y和真实的label,就需要有一个目标函数来计算两者的损失从而指导模型的学习方向。
以SimCLR提出的对比学习框架说明:
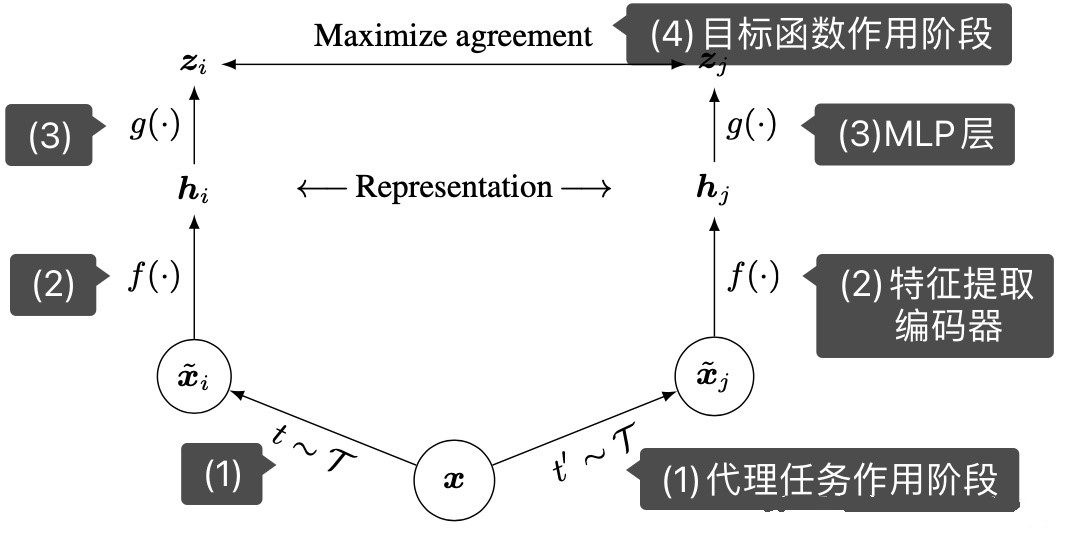
代理任务阶段:对于同一个样本 $x$ ,经过两个代理任务分别生成 $\hat{x}_i$ 和 $\hat{x}_j$ 两个样本,SimCLR属于计算机视觉领域的Paper,文中使用数据增强手段作为代理任务,例如图片的随机裁剪,随机颜色失真,随机高斯模糊, $\hat{x}_i$ 和 $\hat{x}_j$ 就称为一个正样本对。
特征提取器:$f\left( \cdot \right)$ 就是一个编码器,用什么编码器不做限制,SimCLR中使用的时ResNet, $\hat{x}_i$ 和 $\hat{x}_j$ 通过$f\left( \cdot \right)$ 得到 $h_i$ 和 $h_j$。
MLP层(Projector层):通过特征提取之后,再进入MLP层,SimCLR中强调了这个MLP层加上会比不加好,MLP层的输出就是对比学习的目标函数作用的地方,通过MLP层输出 $z_i$ 和 $z_j$。
目标函数作用阶段:对比学习中的损失函数一般是 infoNCE loss, $z_i$ 和 $z_j$ 的损失函数定义如下:
其中,N 代表的是一个batch的样本数,即对于一个batch的N个样本,通过数据增强的得到 N 对正样本对,此时共有 2N 个样本,负样本是什么?SimCLR中的做法就是,对于一个给定的正样本对,剩下的2(N-1)个样本都是负样本,也就是负样本都基于这个batch的数据生成。$sim(z_i,z_j)$ 就是cosin相似度的计算公式。
从上式可以看出,分子中只计算正样本对的距离,负样本只会在对比损失的分母中出现,当正样本对距离越小,负样本对距离越大,损失越小。
温度系数的作用
温度系数虽然只是一个超参数,但它的设置是非常讲究的,直接影响了模型的效果。上式Info NCE loss中 $z_i,z_j$ 的相当于是logits,温度系数可以用来控制logits的分布形状。对于既定的logits分布的形状,当 $\tau$ 值变大,$1 / \tau$ 则就变小,则会使得原来logits分布里的数值都变小,且经过指数运算之后,就变得更小了,导致原来的logits分布变得更平滑。相反,如果 $\tau$ 取得值小,$1 / \tau$ 就变大,原来的logits分布里的数值就相应的变大,经过指数运算之后,就变得更大,使得这个分布变得更集中,更peak。
如果温度系数设的越大,logits分布变得越平滑,那么对比损失会对所有的负样本一视同仁,导致模型学习没有轻重。如果温度系数设的过小,则模型会越关注特别困难的负样本,但其实那些负样本很可能是潜在的正样本,这样会导致模型很难收敛或者泛化能力差。
温度系数的作用是调节对困难样本的关注程度:越小的温度系数越关注于将本样本和最相似的困难样本分开,去得到更均匀的表示。然而困难样本往往是与本样本相似程度较高的,很多困难负样本其实是潜在的正样本,过分强迫与困难样本分开会破坏学到的潜在语义结构,因此,温度系数不能过小
考虑两个极端情况,温度系数趋向于0时,对比损失退化为只关注最困难的负样本的损失函数;当温度系数趋向于无穷大时,对比损失对所有负样本都一视同仁,失去了困难样本关注的特性。
CV中的发展
MoCo-v1:Momentum Contrast for Unsupervised Visual Representation Learning
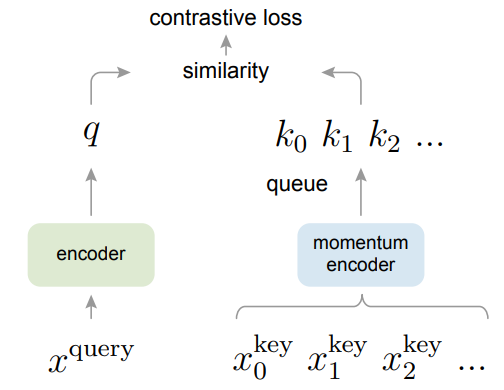
MoCo v1的主要贡献就是把之前的对比学习的一些方法归纳总结成字典查询问题,它提出了两个东西:一个是队列,一个是动量编码器,从而形成了一个又大又一致的字典帮助对比学习。MoCo v1就是用这个队列去取代了原来的memory bank作为一个额外的数据结构去存这个负样本。然后用动量编码器去取代原来loss的约束项从而达到动量更新编码器的目的,而不是动量的去更新那个特征,从而得到更好的结果。
1)它的改进真的是简单有效,而且有很大的影响力,如动量编码器,像SimCLR、BYOL,一直到最新的对比学习的工作都还在使用;
2)它的写作真的是高人一等,如把所有的对比学习方法统一为一个字典查询的框架中。
SimCLR:A Simple Framework for Contrastive Learning of Visual Representations
SimCLR的一个重大创新点就是在特征提取器提取特征后之后,又加了一个叫projector的东西,即g函数,就是一个全连接层跟了一个relu函数。就是这么一个简单的mlp,可以让最后学到的特征在ImageNet上提点将近10个点。我们可以想象有了一个特征h之后,再做一个非线性的变化,就得到另外一个特征z,一般这个z会维度小一点,最后就衡量一下正样本之间是不是能达到最大的一致性。它们采用的是一个叫normalized temperature-scaled的交叉熵函数,normalized指的是在特征后面进行了L2归一化,temperature-scaled就是说在这个loss上乘了一个τ,所以这个loss和之前说的InfoNCE也是非常接近的。
另外这里的projection head也就是g函数只有在训练的时候才用,而当你在做下游任务的时候我们把这个g函数扔掉了,还是只用h去做特征,这样和别的任务就能公平对比了。
1)用了更多的数据增广技术,对对比学习十分有益;
2)加了g函数这个可以学习非线性变化的层;
3)用了更大的batch size来让字典更大,而且训练的更久;
MoCo-v2:Improved Baselines With Momentum Contrastive Learning
MoCo团队看到SimCLR比较好的结果后,发现SimCLR里面的技术都是即插即用型,所以MoCo-v2就都拿过来了。就在MoCo上做很简单的改动,把mlp projectioin head以及更多的数据增强的trick也加进来。
- MoCo相比于SimCLR的这个优越性:就是MoCo可以在较小的batch-size中训练(因为有memory-bank),资源消耗和时间比SimCLR少。
SimCLR-v2:Big Self-Supervised Models are Strong Semi-Supervised Learners
第一个部分就是SimCLR v2,即怎么样通过自监督的对比学习去训练一个大的模型。第二部分就是一旦有了大模型,我们只需要一小部分的这个有标签的数据做一下有监督的微调。一旦微调结束,就等于有了一个teacher模型,就可以去生成很多伪标签,这样就可以在更多无标签的数据上去做这种自学习。
1)无监督学习在模型越大的时候表现会越好,换了一个更大的模型,换了152层的ResNet和selective kernels,来让骨干网络变强
2)MLP层变深会不会更有用,于是经过实验发现2层的projector层最好。
使用动量编码器
SwAC:Unsupervised Learning of Visual Features by Contrasting Cluster Assignment
SwAC的思想就是给定一张图片,如果我去生成不同的视角,我希望可以用一个视角的特征去预测另外一个视角得到的特征,因为所有视角的特征按道理来都应该是非常接近的。这篇文章的做法就是把对比学习和之前聚类的方法合在了一起,聚类的方法本身也是一种无监督的特征表示学习,而且他也是希望相似的物体都聚集在某一个聚类中心附近,而不相似的物体尽量推开推到别的聚类中心,所以跟对比学习做法都比较接近。
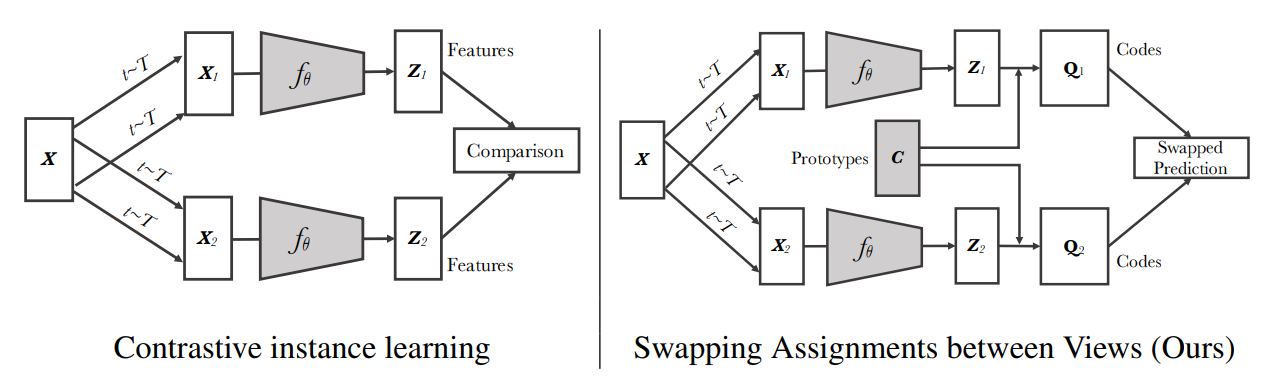
左边:之前对比学习的方法总结,不同的样本对通过编码器提取特征,然后用对比学习学习。
SwAC画到了右边:SwAC认为你直接拿所有图片的这个特征和特征做对比有点原始且有点费资源,因为所有的图片都是自己的类,所以像MoCo有6万个负样本,这还只是个近似(一共有128万个负样本),那我们能不能不去做近似呢?我们能不能借助一些先验信息,不去跟大量的负样本比,而去跟一些更简洁的东西比呢?因此SwAC作者就想出来了,可以和聚类的中心比。聚类中心就是右图画的c,即prototypes,它其实就是一个矩阵,维度是D×K,D是提取出来特征的维度,K是聚类中心的个数,这里取的是3000。
SwAC的前向过程:原始数据,先做数据增强,然后分别过编码器提取出来特征 z1 z2,有了特征之后不是直接在特征上去做对比学习loss,而是说你先通过一个clustering聚类的方法,让你的特征z1 z2和prototypes C去生成一个目标,即q1 q2,q1 q2相当于是一个groundtruth一样的东西,而他真正要做的代理任务是什么呢?如果x1 x2是正样本,那么z1 z2应该很相似,那么按道理来说应该是可以互相去做预测的,即现在用z1和c做点乘,按道理来说是可以去预测q2的,反之亦然。那么点乘之后的结果就是我们的预测,而groundtruth就是之前按照聚类分类得到的这个q1和q2,所以通过这种swapped prediction也就是换位预测的方式,SwAC可以对模型进行训练。
1)跟很多的负样本去做类别,你需要成千上万个负样本,而且即使如此你也只是一个近似。而如果只是跟聚类中心去做对比,可以用几百或最多3000个聚类中心就足以表示。
2)聚类的中心是有明确的语义含义的,而之前只是随机抽样负样本去做对比,那些负样本有的可能还是正样本,而且有时候抽出来的负样本这个类别也不均衡,所以不如聚类中心有效。
BYOL:Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
- 为什么不用负样本在对比学习中这么稀奇呢?是因为在对比学习中,负样本是一个约束,如果你在算目标函数的时候你只有正样本,那其实你的目的就只有一个,那就是让所有相似的物体它们的特征也尽可能相似,那这个时候就有一个很明显的捷径解:即一个模型不论你给它什么输入,它都给你返回同样的输出,那这样他出来的所有特征都是一模一样的,那你拿这个去算对比学习的loss就都是0。而只有加上负样本这个约束,模型才有动力去继续学,因为他输出的都一样的话,那在负样本这边loss就无穷大,所以负样本在对比学习里面是一个必须的东西,防止模型学到一个捷径解,很多论文里把这个叫做model collapse,就是啥都没学到。
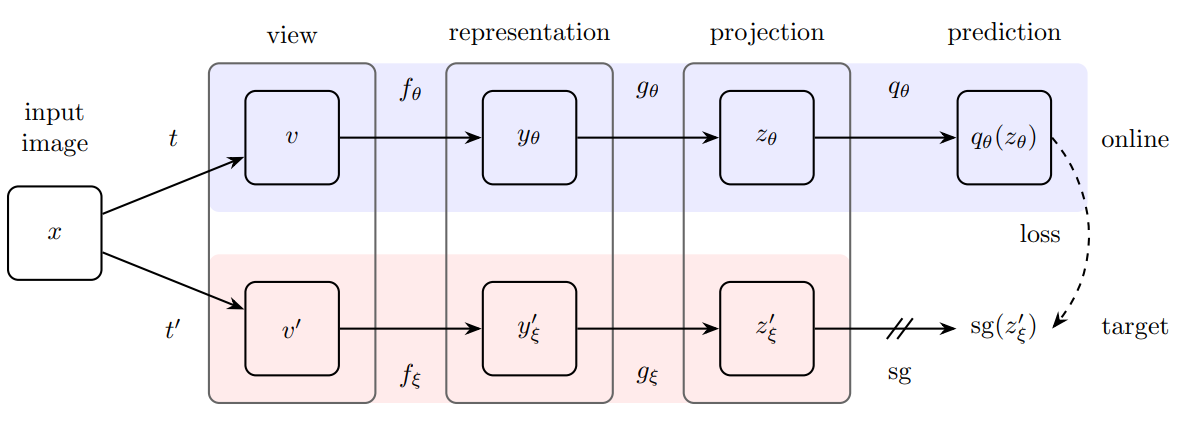
BYOL的模型总览图如上所示,首先有一个mini-batch的输入x,经过两次数据增强得到了 v 和 v’,然后通过编码器得到特征,两个编码器使用一样的结构,但不共享参数,下面的编码器和MoCo一样是通过动量更新的方法更新的。接下来和SimCLR一样,用了一个projection head得到进一步的特征 z。之前的对比学习就是让这两个 z 尽可能接近,但是BYOL没有这么做,又加了一层叫predictor的东西,这个 qθ 和 gθ 网络结构一样,也是一个mlp,这样就得到一个新的特征,即 qθ(zθ),他们想要他们这个预测和下面这个 zξ′尽可能一致,就是把原来一个匹配的问题换成现在一个预测的问题。
代理任务改成了一个视角去预测另一个视角的代理任务。训练网络用的目标函数也很有意思,直接用的mse loss,因为现在就是两个向量,现在想让他们尽可能接近,所以算一个mse loss就可以了。
模型坍塌问题:带BN的BYOL,结果是正确的;没有用BN的话,结果就和随机的差不多。接下来作者发现只要在某一块放了BN,结果就不会太差,因此觉得肯定是BN惹的祸。而且思考出了一个结论:BN是把一个batch的所有数据拿过来算一下均值和方差,然后用这个均值和方差做归一化,那这也就意味着你在算某个正样本的loss的时候,你也看到了其他样本的这个特征,也就是说这里是有信息泄露的,因为有这个信息泄露的存在,所以可以把这个batch里面的其他样本,想象成一个隐式的这个负样本;换句话说,有了BN的时候,BYOL其实不光是正样本在自己跟自己学,他其实也在跟自己做对比,它的对比任务是当前的正样本图片,跟你这个平均图片有什么差别,而这个平均图片,就是batch norm产生的,还有很多图片的总结量。这个就跟SwAV很像了,因为SwAV就是没有跟负样本去比,而是找了一个聚类中心去比,而这里batch norm生成的这种平均图片相当于聚类中心。
SimSiam:Exploring Simple Siamese Representation Learning
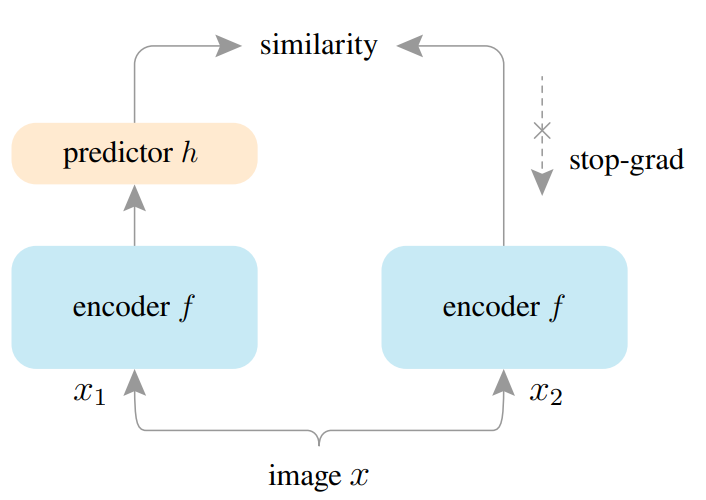
BYOL出来之后,就有很多工作在分析对比学习的成功,因为很多对比学习的工作,好像都是被很多改进堆起来的这个性能,比如projection head、动量编码器、更大的batch size等等。
网络结构如上所示,首先两个编码器的网络结构是一样的,而且是要共享参数的,然后有一个predictor,然后预测另一个特征,和BYOL不一样的就是不需要动量更新。目标函数用的是mse loss,然后预测可以是双向的,即可以用x1出去的特征过predictor预测x2出去的特征也可以反过来。
SimSiam之所以不会模型坍塌,主要就是因为有stop gradient这个操作的存在。