Data_Enhancemenct
Data Enhancement
- 数据增强可以提高泛化能力,但这一过程依赖于数据集,而且需要专门知识。其次,数据增强假定领域内样本都是同一类,且没有对不同类不同样本之间领域关系进行建模。
- 避免过拟合。当数据集具有某种明显的特征,例如数据集中图片基本在同一个场景中拍摄,使用Cutout方法和风格迁移变化等相关方法可避免模型学到跟目标无关的信息。
- 提升模型鲁棒性,降低模型对图像的敏感度。当训练数据都属于比较理想的状态,碰到一些特殊情况,如遮挡,亮度,模糊等情况容易识别错误,对训练数据加上噪声,掩码等方法可提升模型鲁棒性。
- 增加训练数据,提高模型泛化能力。
- 避免样本不均衡。在工业缺陷检测方面,医疗疾病识别方面,容易出现正负样本极度不平衡的情况,通过对少样本进行一些数据增强方法,降低样本不均衡比例
常规弱增强
- 随机缩放,随机按 [0.5, 2.0] 调整图像大小。
- 随机翻转,以 0.5 的概率水平翻转图像。
- 随机裁剪,从图像中随机裁剪一个区域(513 × 513,769 × 769)
常规强增强
- Identity,返回原始图像。
- 反相,将图像像素反相。
- 自动对比度,最大化(正常化)图像对比度。
- 均衡,均衡图像直方图。
- 高斯模糊,使用高斯核对图像进行模糊处理。
- 对比度,以 [0.05, 0.95] 调整图像对比度。
- 锐度,以 [0.05, 0.95] 的幅度调整图像的锐度。
- 色彩,通过 [0.05, 0.95] 增强图像的色彩平衡
- 亮度,以 [0.05, 0.95] 调节图像亮度
- 色调,以 [0.0, 0.5] 的幅度抖动图像的色调
- Posterize,将每个像素降低到 [4,8] 位。
- 日晒化,将图像中所有高于阈值 [1,256] 的像素反相。
- CutMix,
空间几何变换
翻转,翻转包括水平翻转和垂直翻转。
crop,裁剪图片的感兴趣区域(ROI),通常在训练的时候,会采用随机裁剪的方法,下图为随机裁剪4次的效果。
旋转,对图像做一定角度对旋转操作,看看效果。
缩放变形,随机选取图像的一部分,然后将其缩放到原图像尺度。
仿射变换,同时对图片做裁剪、旋转、转换、模式调整等多重操作。
视觉变换,对图像应用一个随机的四点透视变换。
- 分段仿射(PiecewiseAffine),分段仿射在图像上放置一个规则的点网格,根据正态分布的样本数量移动这些点及周围的图像区域。
噪声类
随机噪声是在原来的图片的基础上,随机叠加一些噪声。
- 高斯噪声
CoarseDropout,在面积大小可选定、位置随机的矩形区域上丢失信息实现转换,所有通道的信息丢失产生黑色矩形块,部分通道的信息丢失产生彩色噪声。
SimplexNoiseAlpha,产生连续单一噪声的掩模后,将掩模与原图像混合。
FrequencyNoiseAlpha。在频域中用随机指数对噪声映射进行加权,再转换到空间域。在不同图像中,随着指数值逐渐增大,依次出现平滑的大斑点、多云模式、重复出现的小斑块。
模糊类
减少各像素点值的差异实现图片模糊,实现像素的平滑化。
- 高斯模糊
ElasticTransformation,根据扭曲场的平滑度与强度逐一地移动局部像素点实现模糊效果。
HSV对比度变换,通过向HSV空间中的每个像素添加或减少V值,修改色调和饱和度实现对比度转换。
RGB颜色扰动,将图片从RGB颜色空间转换到另一颜色空间,增加或减少颜色参数后返回RGB颜色空间。
随机擦除法,对图片上随机选取一块区域,随机地擦除图像信息。
超像素法(Superpixels),在最大分辨率处生成图像的若干个超像素,并将其调整到原始大小,再将原始图像中所有超像素区域按一定比例替换为超像素,其他区域不改变。
转换法(invert),按给定的概率值将部分或全部通道的像素值从v设置为255-v。
边界检测(EdgeDetect),检测图像中的所有边缘,将它们标记为黑白图像,再将结果与原始图像叠加。
GrayScale,将图像从RGB颜色空间转换为灰度空间,通过某一通道与原图像混合。
锐化(sharpen)与浮雕(emboss),对图像执行某一程度的锐化或浮雕操作,通过某一通道将结果与图像融合。
Mixup: BEYOND EMPIRICAL RISK MINIMIZATION

- 代码:GitHub - facebookresearch/mixup-cifar10: mixup: Beyond Empirical Risk Minimization
- 代码1:https://github.com/tengshaofeng/ResidualAttentionNetwork-pytorch/blob/master/Residual-Attention-Network/train_mixup.py
- 论文:https://arxiv.org/pdf/1710.09412.pdf
- 参考链接:https://www.zhihu.com/question/308572298,https://blog.csdn.net/u013841196/article/details/81049968,https://blog.csdn.net/sinat_36618660/article/details/101633504?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_default&utm_relevant_index=1

Method

对于输入的一个batch的待测图片images,我们将其和随机抽取的图片进行融合,融合比例为lam,得到混合张量inputs;
第1步中图片融合的比例lam是[0,1]之间的随机实数,符合beta分布,相加时两张图对应的每个像素值直接相加,即 inputs = lam images + (1-lam) images_random
将上面得到的混合张量inputs传递给model得到输出张量outpus,随后计算损失函数时,我们针对两个图片的标签分别计算损失函数,然后按照比例lam进行损失函数的加权求和,即loss = lam criterion(outputs, targets_a) + (1 - lam) criterion(outputs, targets_b);
Mixup核心思想:两张图片采用比例混合,label也需要按照比例混合
计算损失函数有两个视角:首先应用于目标检测
- 对相应的lable进行线性加权,由于lable采用one-hot编码可以理解为对k个类别的每个类给出样本属于该类的概率。加权以后就变成了”two-hot”,也就是认为样本同时属于混合前的两个类别
- 不混合label,而是用加权的输入在两个label上分别计算cross-entropy loss,最后把两个loss加权作为最终的loss。由于cross-entropy loss的性质,这种做法和把label线性加权是等价的(代码采用这种方式)
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17for i,(images,target) in enumerate(train_loader):
# 1.input output
images = images.cuda(non_blocking=True)
target = torch.from_numpy(np.array(target)).float().cuda(non_blocking=True)
# 2.mixup
# 一般情况下,config.alpha=1,是个超参数
alpha=config.alpha
lam = np.random.beta(alpha,alpha)
index = torch.randperm(images.size(0)).cuda()
inputs = lam*images + (1-lam)*images[index,:]
targets_a, targets_b = target, target[index]
outputs = model(inputs)
loss = lam * criterion(outputs, targets_a) + (1 - lam) * criterion(outputs, targets_b)
# 3.backward
optimizer.zero_grad() # reset gradient
loss.backward()
optimizer.step() # update parameters of net
Cutout:Improved Regularization of Convolutional Neural Networks with Cutou

Motivation
这篇文章的出发点除了解决遮挡问题外,还有从dropout上得到启发(所以也称为Cutout)。众所周知,Dropout随机隐藏一些神经元,最后的网络模型相当于多个模型的集成。类似于dropout的思路,这篇文章将drop用在了输入图片上,并且drop掉连续的区域——即矩形区域。通过patch的遮盖让网络学习到遮挡的特征。cutout不仅能够让模型学习到如何辨别他们,同时还能更好地结合上下文从而关注一些局部次要的特征。作为一个正则化方法,防止CNN过拟合。cutcout方法很简单,就是在训练的时候,在随机位置应用一个方形矩阵。作者认为这种技术鼓励网络去利用整个图片的信息,而不是依赖于小部分特定的视觉特征。
Cutout 出发点和随机擦除一样,也是模拟遮挡,目的是提高泛化能力,实现上比Random Erasing(类似的数据增强方法)简单,随机选择一个固定大小的正方形区域,然后采用全0填充就OK了,当然为了避免填充0值对训练的影响,应该要对数据进行中心归一化操作,norm到0。
Method
需要注意的是作者发现cutout区域的大小比形状重要,所以cutout只要是正方形就行,非常简单。具体操作是利用固定大小的矩形对图像进行遮挡,在矩形范围内,所有的值都被设置为0,或者其他纯色值。而且擦除矩形区域存在一定概率不完全在原图像中的(论文设置50%)
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31class Cutout(object):
"""Randomly mask out one or more patches from an image.
Args:
n_holes (int): Number of patches to cut out of each image. default 1
length (int): The length (in pixels) of each square patch. default 16
"""
def __init__(self, n_holes, length):
self.n_holes = n_holes
self.length = length
def __call__(self, img):
"""
Args:
img (Tensor): Tensor image of size (C, H, W).
Returns:
Tensor: Image with n_holes of dimension length x length cut out of it.
"""
h = img.size(1)
w = img.size(2)
mask = np.ones((h, w), np.float32)
for n in range(self.n_holes):
y = np.random.randint(h)
x = np.random.randint(w)
y1 = np.clip(y - self.length // 2, 0, h)
y2 = np.clip(y + self.length // 2, 0, h)
x1 = np.clip(x - self.length // 2, 0, w)
x2 = np.clip(x + self.length // 2, 0, w)
mask[y1: y2, x1: x2] = 0.
mask = torch.from_numpy(mask)
mask = mask.expand_as(img)
img = img * mask
return img

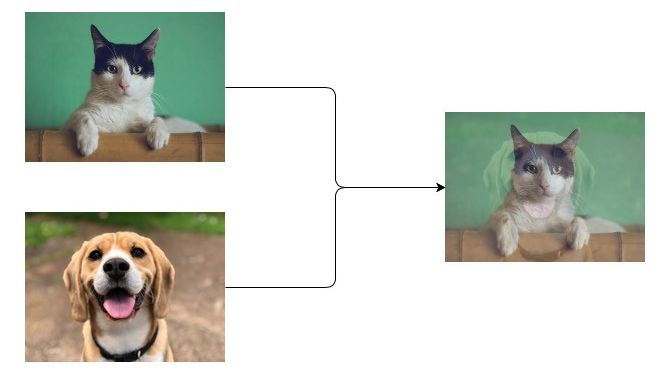
CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features

Motivation
区域的丢弃策略(Reginal dropout strategies)能够增强卷积神经网络分类器的性能。
- 优点: 该策略能够使得模型更有效的关注目标的明显部分,有好的泛化和目标定位能力。
- 缺点: 利用黑色像素或者随机噪声填充移除区域,这样的操作在训练过程中容易导致信息的缺失和无效性。
- 解决方法: 提出了CutMix——使用训练集中的图像填补移除区域
CutMix最大程度的利用了同一张图像上的两种不同图像信息。具有更好的分类性能和目标定位功能。CutMix在填充了训练集中的其他照片的同时,label也进行了相同比例转换。
- CutMix采用了cutout的局部融合思想,并不是采用全0的mask填充,而是采用另外一张图片的相同大小区域填充,就是混合两张图的局部区域,并且采用了mixup的混合label策略,看起来比较make sense
Method

代码
整体算法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23for i, (input, target) in enumerate(train_loader):
# measure data loading time
data_time.update(time.time() - end)
input = input.cuda()
target = target.cuda()
r = np.random.rand(1)
if args.beta > 0 and r < args.cutmix_prob:
# 1.设定lambda的值,服从beta分布
lam = np.random.beta(args.beta, args.beta) # args.beta 超参数 default 1
# 2.找到两个随机样本
rand_index = torch.randperm(input.size()[0]).cuda()
target_a = target
target_b = target[rand_index]
# 3.生成裁剪区域B
bbx1, bby1, bbx2, bby2 = rand_bbox(input.size(), lam)
# 4.将原有的样本A中的B区域,替换成样本B中的B区域
input[:, :, bbx1:bbx2, bby1:bby2] = input[rand_index, :, bbx1:bbx2, bby1:bby2]
# 5.根据裁剪区域坐标框的值调整lamda的值
lam = 1 - ((bbx2 - bbx1) * (bby2 - bby1) / (input.size()[-1] * input.size()[-2]))
# 6.将生成的新的训练样本丢到模型中进行训练
output = model(input)
# 7.按lamda值分配权重
loss = criterion(output, target_a) * lam + criterion(output, target_b) * (1. - lam)
裁剪区域B的坐标值函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17def rand_bbox(size, lam):
W = size[2]
H = size[3]
# 论文里的公式2:求出B的rw,rh
cut_rat = np.sqrt(1. - lam)
cut_w = np.int(W * cut_rat)
cut_h = np.int(H * cut_rat)
# 论文里的公式2:求出B的rx,ry
cx = np.random.randint(W)
cy = np.random.randint(H)
# 限制坐标区域不超过样本大小
bbx1 = np.clip(cx - cut_w // 2, 0, W)
bby1 = np.clip(cy - cut_h // 2, 0, H)
bbx2 = np.clip(cx + cut_w // 2, 0, W)
bby2 = np.clip(cy + cut_h // 2, 0, H)
# 返回裁剪B区域的坐标值
return bbx1, bby1, bbx2, bby2

- 热力图:CutMix的操作使得模型能够从一幅图像上的局部视图上识别出两个目标,提高训练的效率。由图可以看出,Cutout能够使得模型专注于目标较难区分的区域(腹部),但是有一部分区域是没有任何信息的,会影响训练效率;Mixup的话会充分利用所有的像素信息,但是会引入一些非常不自然的伪像素信息。
总结
- Mixup:将随机的两张样本按比例混合,分类的结果按比例分配;
- Cutout:随机的将样本中的部分区域cut掉,并且填充0像素值,分类的结果不变;
CutMix:就是将一部分区域cut掉但不填充0像素而是随机填充训练集中的其他数据的区域像素值,分类结果按一定的比例分配
上述三种数据增强的区别:cutout 和 cutmix 就是填充区域像素值的区别;mixup和cutmix是混合两种样本方式上的区别:mixup是将两张图按比例进行插值来混合样本,cutmix是采用cut部分区域再补丁的形式去混合图像,不会有图像混合后不自然的情形
CutMix优点:
- 在训练过程中不会出现非信息像素,从而能够提高训练效率;
- 保留了regional dropout的优势,能够关注目标的non-discriminative parts;
- 通过要求模型从局部视图识别对象,对cut区域中添加其他样本的信息,能够进一步增强模型的定位能力;
- 不会有图像混合后不自然的情形,能够提升模型分类的表现;
- 训练和推理代价保持不变。
more data enhancement