SETR:Rethinking_Semantic_Segmentation_from_a_Sequence-to-Sequence_Perspective_with_Transformers
Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers

introduction
最新的语义分割方法采用具有编码器-解码器体系结构的全卷积网络(FCN)。编码器逐渐降低空间分辨率,并通过更大的感受野学习更多的抽象/语义视觉概念。由于上下文建模对于分割至关重要,因此最新的工作集中在通过扩张/空洞卷积或插入注意力模块来增加感受野。但是,基于编码器-解码器的FCN体系结构保持不变。
在本文中,我们旨在通过将语义分割视为序列到序列的预测任务来提供替代视角。具体来说,我们部署一个纯 transformer(即,不进行卷积和分辨率降低)将图像编码为一系列patch。通过在 transformer的每一层中建模全局上下文,此编码器可以与简单的解码器组合以提供功能强大的分割模型,称为SEgmentation TRansformer(SETR)。
一个标准的FCN分割模型有一个编码器-解码器结构:编码器用于特征表示学习,而解码器用于编码器产生的特征表示的像素级分类。编码器由堆叠的卷积层组成,特征图的分辨率逐渐降低,编码器能够以逐渐增加的感受野学习更多的抽象/语义视觉概念。
优点:translation equivariance:尊重了成像过程的本质,支持了模型对看不见的图像数据的泛化能力
局部性:通过跨空间共享参数来控制模型的复杂性。
缺点:感受野有限,难以学习无约束场景图像中的语义分割的长期依赖信息。
解决方法:
直接操作卷积运算:大内核尺寸(large kernel sizes),atrous卷积和图像/特征金字塔。
注意力模块集成到FCN架构中:对特征图中所有像素的全局交互进行建模。当应用于语义分割时,通常是是将注意力模块与位于顶部的注意力层结合到FCN架构中。不改变FCN模型结构的本质:编码器下采样输入的空间分辨率,用于区分语义类别的低分辨率特征映射;解码器将特征表示上采样为全分辨率分割映射。
本文中,我们用纯transformer 取代空间分辨率逐渐降低的基于堆叠卷积层的编码器,这种编码器将输入图像视为由学习到的面片嵌入表示的图像面片序列,并使用全局自关注建模对该序列进行转换,以进行有区别的特征表示学习。
Methods and Creativity
问题
典型的语义分割Encoder-Decoder结构以多次下采样损失空间分辨率为代价来抽取局部/全局特征。网络Layer一旦固定,每一层的感受野是受限的,因此要获得更大范围的语义信息,理论上需要更大的感受野即更深的网络结构。
如何既能够抽取全局的语义信息,又能尽量不损失分辨率,一直是语义分割的难点
解决方法
- 用常用于NLP领域的transformer作为Encoder来抽取全局的语义信息(整个过程不损失image分辨率),代替传统FCN的编码部分,从序列-序列学习的角度,为语义分割问题提供了一种新的视角;
- 将图像序列化处理,利用Transformer框架、完全用注意力机制来实现Encoder的功能;
- 提出三种复杂度不同的Decoder结构
整体网络架构
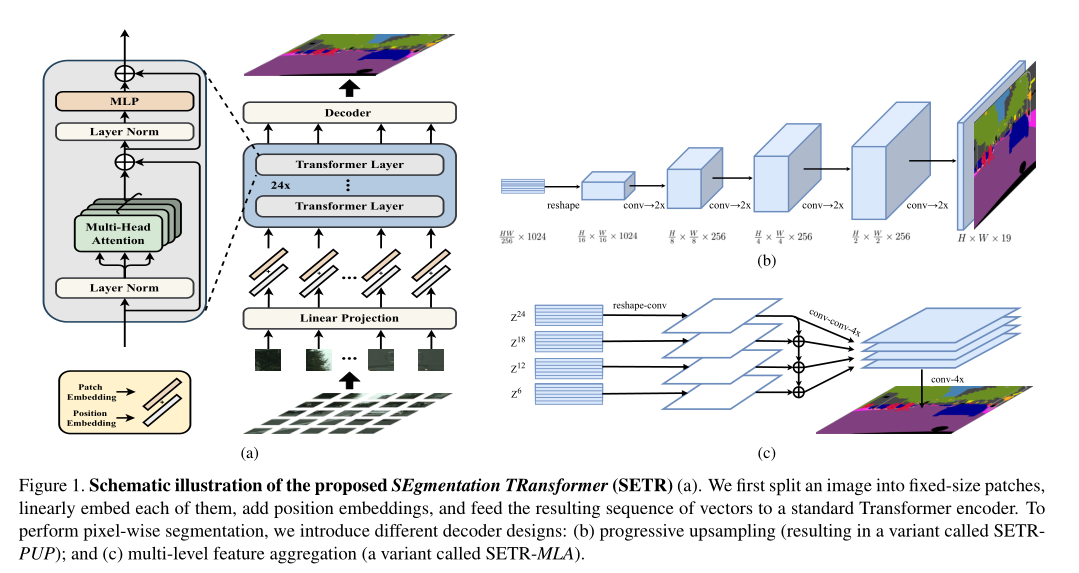
part 1:图像序列化处理
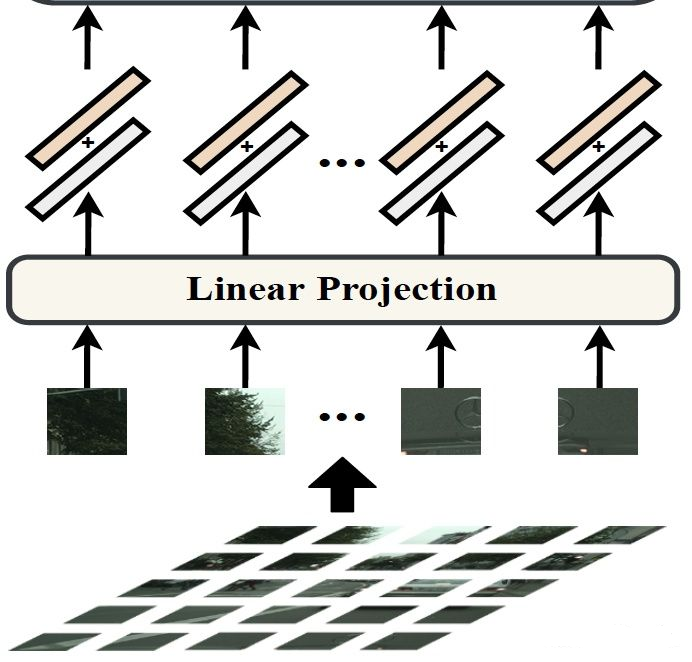
image to sequenc,因为NLP中transformation的输入是一维序列,所以需要把图像(H W C)转换成 1D序列。
1): 按pixel-wise进行flatten。考虑到计算量问题所以此方法不通。
2): 按patch-wise进行flatten。本文采用此方法。
1、输入图像的大小 H W 3(256 256 3)的大小,patch_size = 16 16,因此图像序列化为 256/16 256 /16 = 256个 (16 16 3)的图片大小
2、向量化后的patchp_i经过Linear Projectionfunction得到向量e_i ,旁边注释e_i是patch embedding,p_i是position embedding。
- part 2:Transformer
这边采用的是纯 Transformer 的encoder结构,只不过中间重复叠用了24次,具体的使用可以查看 PIT, PVT,Swin Transformer 的总结文档。
part3 Decoder
本文就提出了三种不一样的 decoder 的设计,分别如下
Navite Upsampling(Naive)
2-layer:(1 1)conv + sync batch norm(w/ReLU)+ (1 1)conv
将Transformer输出的特征维度降到分类类别数后经过双线性上采样恢复原分辨率
Progressive UPsampling (PUP)
交替使用卷积层和两倍上采样操作,为了从
H/16 × W/16 × 1024恢复到H × W × 19(19是cityscape的类别数) 需要4次操作,以恢复到原分辨率。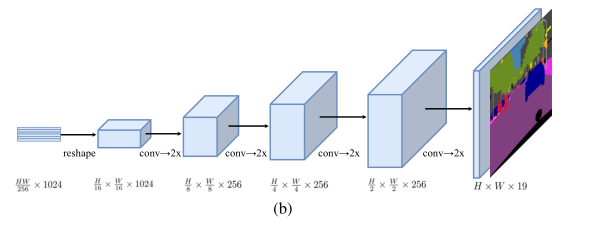
Multi-Level feature Aggregation (MLA)
首先将Transformer的输出
{Z1,Z2,Z3…ZLe}均匀分成M等份,每份取一个特征向量。如下图,24个transformer的输出均分成4份,每份取最后一个,即{Z6,Z12,Z18,Z24}.后面的Decoder只处理这些取出的向量。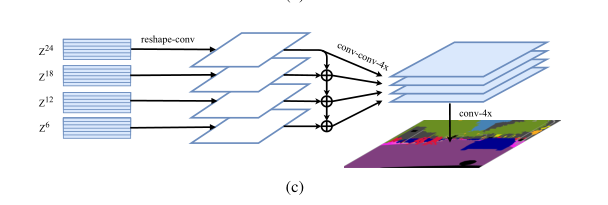
具体步骤:
1.2D —> 3D。将
ZL从2D(H × W)/256 × C恢复到3DH/16 × W/16 × C2.经过3-layer的卷积
1 × 1, 3 × 3, and 3 × 33.双线性上采样
4×4.自上而下的融合。以增强
Zl之间的相互联系,如上图最后一个Zl理论上拥有全部上面三个feature的信息,融合即cat5.
3 × 36.双线性插值
4×恢复至原分辨率。损失函数设计
totalloss = auxiliary loss + main loss
其中main loss为
CrossEntropyLoss,auxiliary loss在17年CVPR有提及
contributions
- We reformulate the image semantic segmentation problem from a sequence-to-sequence learning perspective, offering an alternative to the dominating encoder-decoder FCN model design.
- As an instantiation, we exploit the transformer framework to implement our fully attentive feature representation encoder by sequentializing images.
- To extensively examine the self-attentive feature presentations, we further introduce three different decoder designs with varying complexities. Extensive experiments show that our SETR models can learn superior feature representations as compared to different FCNs with and without attention modules, yielding new state of the art on ADE20K (50.28%), Pascal Context (55.83%) and competitive results on Cityscapes. Particularly, our entry is ranked the 1stplace in the highly competitive ADE20K test server leaderboard.
Experiments
- 在Cityscapes/ADE20K/PASCAL Context三个数据集上进行了实验。实验结果优于用传统FCN(with & without attention module)抽特征的方法
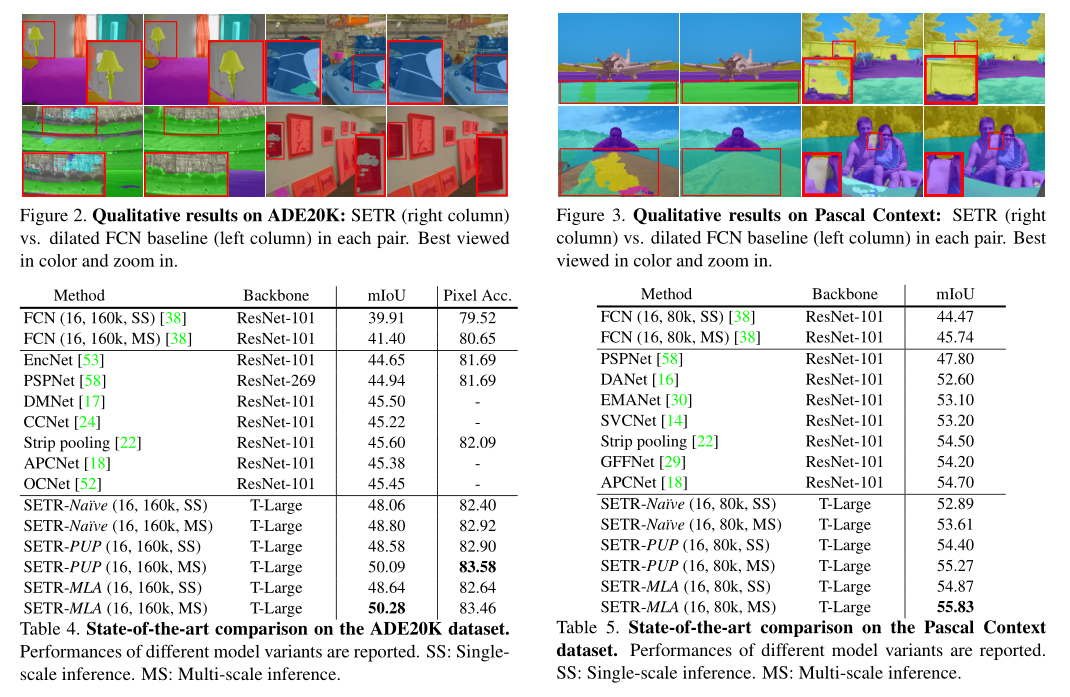
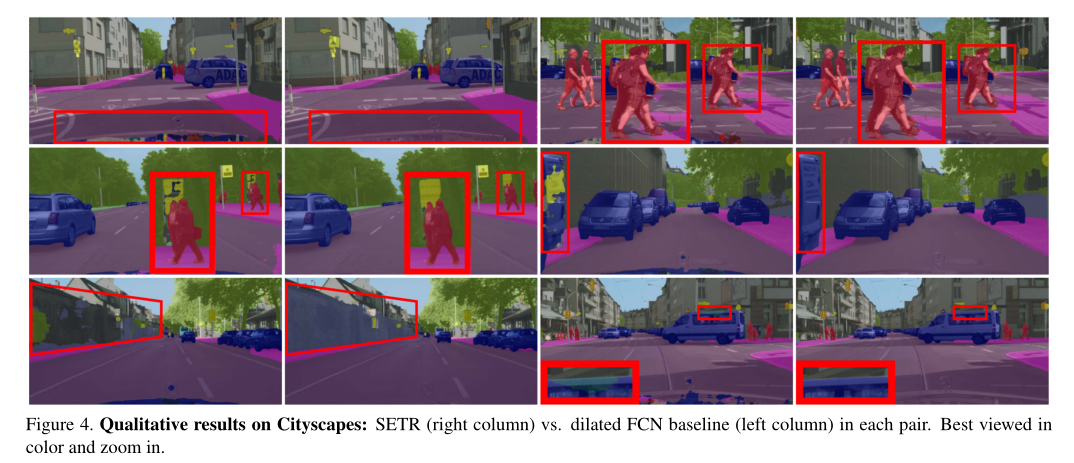
- 可视化结果
- 还有较多的 Ablation experiments,以验证参数选择的有效性。具体的可以查看论文详细内容
Rethingking
- 卷积操作的感受野有限是传统FCN体系结构的一个内在限制。为突破该限制,逐渐提出两类方法
- 改变卷积:包括增大卷积核kernel_size、Non-local(跟本文有点像,每次抽取的都是全局特征)和特征金字塔。例如DeepLab引入空洞卷积/SPP/ASPP。
- 将注意力模块集成到FCN体系结构中:一次对所有像素的全局信息抽取特征。例如PSANet提出点向空间注意模块、DANet嵌入channel attention和spatial attention。
- 有人提到,本文是把ViT模型原封不动迁移过来了,替换了encoder,虽带来了精度的提升但模型的计算量和参数量都非常大。
ViT(Vision Transformer)首次证明了纯基于transformer的图像分类模型可以达到sota。
- CNN是通过不断地堆积卷积层来完成对图像从局部信息到全局信息的提取,不断堆积的卷积层慢慢地扩大了感受野直至覆盖整个图像;但是transformer并不假定从局部信息开始,而且一开始就可以拿到全局信息,学习难度更大一些,但transformer学习长依赖的能力更强。
- CNN结构更适合底层特征,Transformer更匹配高层语义。二者无绝对差别,就是看问题的尺度差异,本质都是消息传递。
- 现在对transformer理解还不充分,为啥Transformer之后没有改变分辨率,还要用Decoder来恢复原image的分辨率(得看看transformer那篇论文,或者评论区有好心人解答一下嘛)。