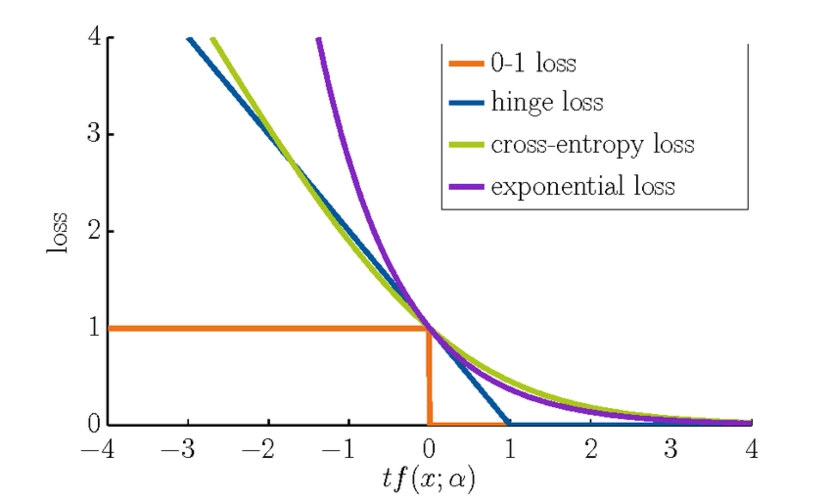
simpler-is-better:Few-shot_Semantic_Segmentation_with_Classifier_Weight_Transformer
Simpler is Better: Few-shot Semantic Segmentation with Classifier Weight Transformer

introduction
得益于大型的标签数据和深度学习算法的发展,语义分割方法近几年取得了很大的进步。但这些方法有两个局限:
1)过度依赖带标签数据,而这些数据的获得通常消耗大量人力物力;
2)训练好的模型并不能处理训练过程中未见的新类别。
面对这些局限,小样本语义分割被提出来,它的目的是通过对少量样本的学习来分割新类别。一般来说,小样本语义分割方法是通过用训练数据模拟测试环境进行元学习使得训练的模型有很好的泛化能力,从而在测试时可以仅仅利用几个样本的信息来迭代模型完成对新类别的分割。具体地,小样本分割模型是在大量的模拟任务上进行训练,每个模拟任务有两个数据组:Support set and Query set。Support set 是有标签的K-shot样本,而Query set只在训练的时候有标签。这样的模拟任务可以有效地模拟测试环境
- 针对元学习的概念,可以参考:https://zhuanlan.zhihu.com/p/289043310
- 针对小样本学习的一些概念,可以参考:https://zhuanlan.zhihu.com/p/84290146
Methods and Creativity
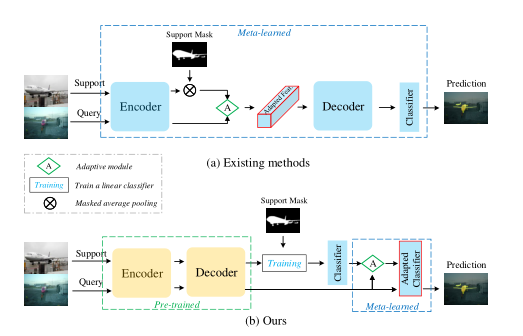
一个小样本分类系统一般由三部分构成:编码器,解码器和分类器。其中,前两个模块模型比较复杂,最后一个分类器结构简单。我们发现现存的小样本分类方法通常在元学习的过程中更新所有模块或者除编码器外的模块,而所利用更新模块的数据仅仅有几个样本。在这样的情况下,我们认为模型更新的参数量相比于数据提供的信息量过多,从而不足以优化模型参数。基于此分析,我们提出了一个全新的元学习训练范式,即只对分类器进行元学习。为了方便读者更好的理解,论文给出了两种方法的对比,如下图,图(a)为传统方法,要训练三个模块,图(b)为本文方法,编码器解码器在经过大量有标记数据训练后便冻结,只调整分类器权重
具体地,我们采用常规的分割方法对编码器和解码器进行训练,训练后在元学习的过程中不在更新。这是基于我们的假设:在大量标签数据训练下的模型可以提取有辨别性的特征,对一些新类别也有效,这也可以解释很多方法直接使用ImageNet预训练的模型进行特征提取。在分析数据的时候,我们发现Support set和Query set的数据有时有较大的类内差异,如下图。同样的类别,不同的角度即可产生很大的区别。这就使得利用Support set迭代的模型不能很好地作用在Query set上。

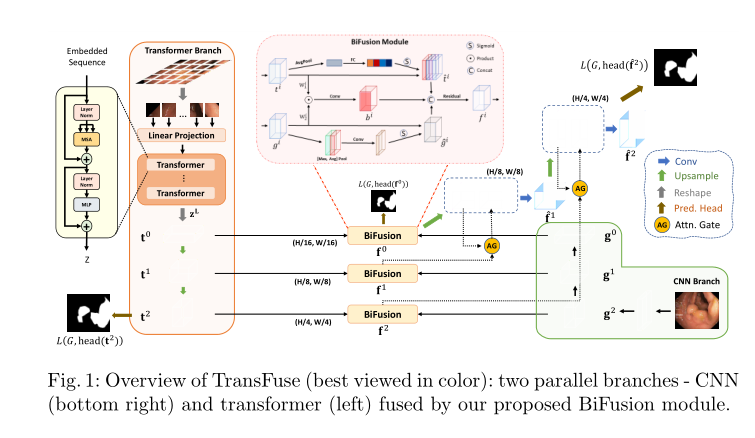
为了解决这个问题,我们提出了Classifier Weight Transformer来动态地利用Query set的特征信息来进一步更新分类器模块,从而提升分割任务性能。一个少镜头分割模型通常由三个模块组成:编码器、解码器和分类器。为了学习适应新类别,现有方法通常在编码器在 ImageNet 上进行预训练后对整个模型进行元学习 [23]。在情节训练阶段,模型的所有三个部分都是元学习的。训练后,给定一个带有带注释的支持集图像和用于测试的查询图像的新类,该模型有望使所有三个部分都适应新类。由于只有很少的带注释的支持集图像和复杂且相互关联的三部分,这种适应通常是次优的。为了克服这些限制,我们提出了一个分两个阶段的简单而有效的训练范式。在第一阶段,我们通过监督学习对编码器和解码器进行预训练,以获得更强的特征表示。在第二阶段,连同冻结的编码器和解码器,我们仅对分类器进行元训练。这是因为我们认为预训练的特征表示部分(即编码器和解码器)足以泛化到任何看不见的类别;因此,少样本语义分割的关键在于调整二元分类器(分离前景和背景像素),而不是从少样本样本中调整整个模型。我们方法的概述如下图所示。具体的算法参考原文。
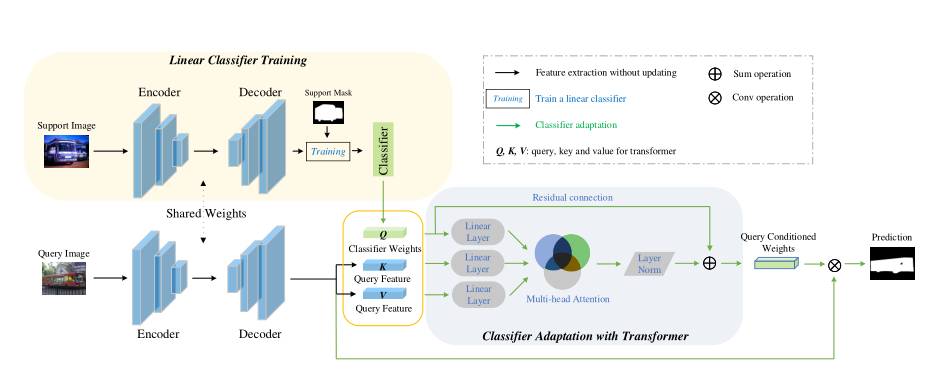
者假设,一个学习了大量图片和信息的传统分割网络已经能够从任何一张图片中捕捉到充分的,有利于区分背景和前景的信息,无论训练时是否遇到了同类的图。那么面对少样本的新类时,只要对分类器进行元学习即可。 对于分类器的学习,作者提出了一种分类器权重转移方法CWT,根据每一张查询集图象,临时调整分类器参数。借助Transformer的思想,作者将分类器权重转化为Query,将图象提取出来的特征转化为Key和Value,然后根据这三个值调整分类器权重,最后通过残差连接,与原分类器参数求和
本文提出的元学习名为episodic training。一般来说,本文提出的元学习针对是小样本的类进行学习。元学习分两步
- 第一步是内循环,和预训练一样,根据支持集上的图片和mask进行训练,不过只修改分类器参数。文中指出,当新类样本数够大时,只使用外循环,即只更新分类器,就能匹敌SOTA,但是当面对小样本时,表现就不尽如人意。
- 第二步是外循环,根据每一副查询图片,微调分类器参数,而且微调后的参数只针对这一张查询图片,不能用于其他查询图象,也不覆盖修改原分类器参数。
contributions
- We propose a novel model training paradigm for few-shot semantic segmentation. Instead of meta-learning the whole, complex segmentation model, we focus on the simplest classifier part to make new-class adaptation more tractable.
- We introduce a novel meta-learning algorithm that leverages a Classifier Weight Transformer (CWT) for adapting dynamically the classifier weights to every query sample.
- Extensive experiments with two popular backbones (ResNet-50 and ResNet-101) show that the proposed methodyieldsa newstate-of-the-artperformance, often surpassing existing alternatives, especially on 5-shot case, by a large margin. Further, under a more challenging yet practical cross-domain setting, the margin becomes even bigger.
Experiments
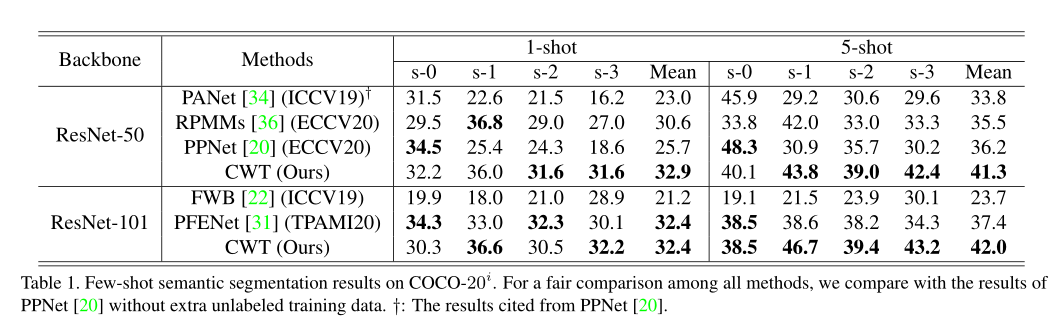
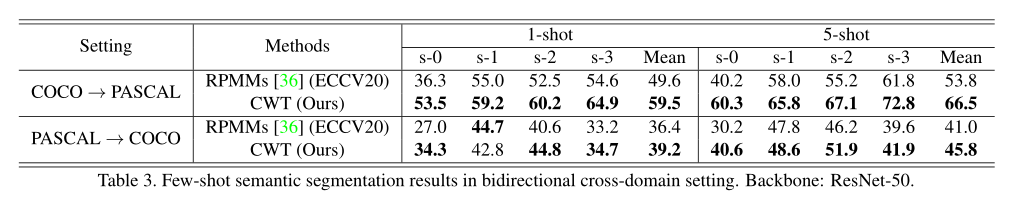
- 在两个标准小样本分割数据集PASCAL和COCO上,我们的方法在大多数情况下取得了最优的结果
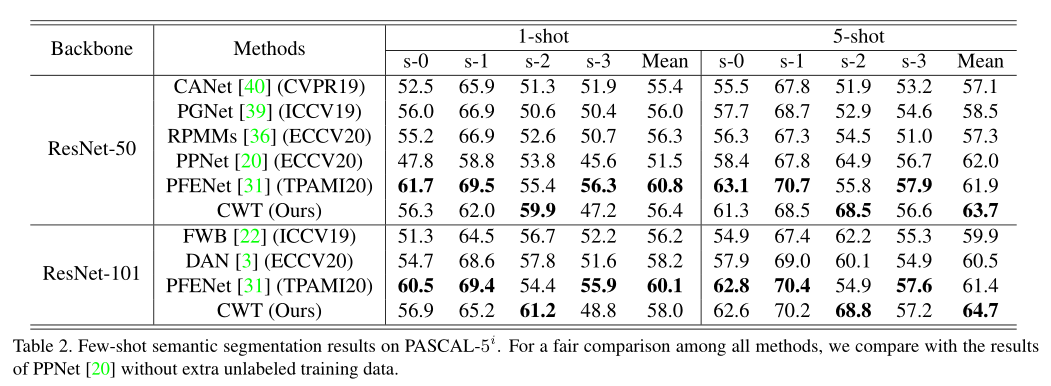
- 跨数据集的情景下测试了我们模型的性能,可以看出我们的方法展示了很好的鲁棒性
- 可视化结果
- 还有较多的 Ablation experiments,以验证参数选择的有效性。具体的可以查看论文详细内容
Rethingking
提出了一种新的元学习训练范式来解决小样本语义分割问题。相比于现有的方法,这种方法更加简洁有效,只对分类器进行元学习。为了解决类内差异问题,我们提出Classifier Weight Transformer来利用Query特征信息来迭代分类器,从而获得更加鲁棒的分割效果。通过大量的实验,我们证明了方法的有效性。针对我们现在的创新点,找到存在的问题,采取简便的方法提升性能未必不是一个新的思路,就拿现在这个而言,并没有对编码器-解码-分类器三个进行元学习,而是只针对其中最简单的分类器进行创新,也采纳了transformer,也算是transformer的一个应用把。果然现在在cv领域transformer大放异彩,针对这种思想,之前也看过类似输入网络的图像大小对性能的影响,也看过动态预测调整输入图片大小的预测,也是一种思路,所以咋创新方面不用单单停留在网络的结构上,而是应该放在整体的架构的,因为任何一处的改变都可能对最后的分割性能产生不一样的影响。道阻且长,望君继续努力。