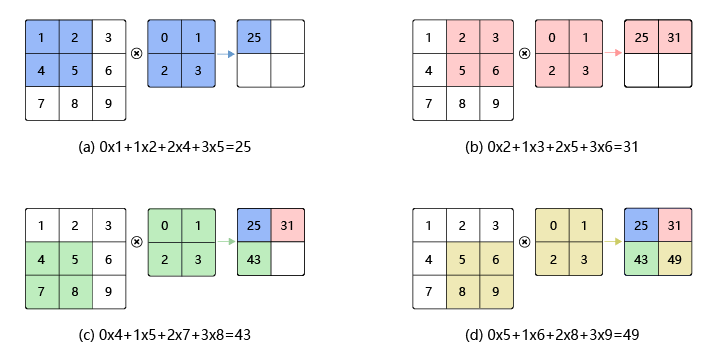
BFS和DFS模板
首先,总结一定的模板做题是十分有作用的,善于总结才是我们加强算法能力的表现。做总结可以提高我们的代码能力,可以比较快速解决算法问题,也会更加清晰算法的流程!!十分有必要!!
BFS的模板:
- 1、如果不需要确定当前遍历到了哪一层,BFS 模板如下。
1 | while queue 不空: |
- 2、如果要确定当前遍历到了哪一层,BFS 模板如下。 这里增加了 level 表示当前遍历到二叉树中的哪一层了,也可以理解为在一个图中,现在已经走了多少步了。size 表示在当前遍历层有多少个元素,也就是队列中的元素数,我们把这些元素一次性遍历完,即把当前层的所有元素都向外走了一步。
1 | level = 0 |
DFS模板(回溯)
- 1、最本质的法宝是“画图”,千万不能偷懒,拿纸和笔“画图”能帮助我们更好地分析递归结构,这个“递归结构”一般是“树形结构”,而符合题意的解正是在这个“树形结构”上进行一次“深度优先遍历”,这个过程有一个形象的名字,叫“搜索”;我们写代码也几乎是“看图写代码”,所以“画树形图”很重要。
- 2、然后使用一个状态变量,一般我习惯命名为 path、pre ,在这个“树形结构”上使用“深度优先遍历”,根据题目需要在适当的时候把符合条件的“状态”的值加入结果集;这个“状态”可能在叶子结点,也可能在中间的结点,也可能是到某一个结点所走过的路径。
- 3、在某一个结点有多个路径可以走的时候,使用循环结构。当程序递归到底返回到原来执行的结点时,“状态”以及与“状态”相关的变量需要“重置”成第 1 次走到这个结点的状态,这个操作有个形象的名字,叫“回溯”,“回溯”有“恢复现场”的意思:意即“回到当时的场景,已经走过了一条路,尝试走下一条路”。第 2 点中提到的状态通常是一个列表结构,因为一层一层递归下去,需要在列表的末尾追加,而返回到上一层递归结构,需要“状态重置”,因此要把列表的末尾的元素移除,符合这个性质的列表结构就是“栈”(只在一头操作)。
- 4、当我们明确知道一条路走不通的时候,例如通过一些逻辑计算可以推测某一个分支不能搜索到符合题意的结果,可以在循环中 continue 掉,这一步操作叫“剪枝”。“剪枝”的意义在于让程序尽量不要执行到更深的递归结构中,而又不遗漏符合题意的解。因为搜索的时间复杂度很高,“剪枝”操作得好的话,能大大提高程序的执行效率。“剪枝”通常需要对待搜索的对象做一些预处理,例如第 47 题、第 39 题、第 40 题、第 90 题需要对数组排序。“剪枝”操作也是这一类问题很难的地方,有一定技巧性。总结一下:“回溯” = “深度优先遍历” + “状态重置” + “剪枝”,写好“回溯”的前提是“画图”。因此,非要写一个模板,我想它可能长这个样子:
1 | def backtrack(待搜索的集合, 递归到第几层, 状态变量 1, 状态变量 2, 结果集): |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 sevenboy!