TransFuse:Fusing_Transformers_and_CNNs_for_Medical_Image_Segmentation
TransFuse: Fusing Transformers and CNNs for Medical Image Segmentation

introduction
传统CNN网络很难捕获长距离的依赖关系,而且一味的加深网络的深度会带来大量的计算冗余。
文章提出了一种并行分支的TransFuse网络,结合transformer和CNN两种网络架构,能同时捕获全局依赖关系和低水平的空间细节,文中还提出了一种BiFusion module用来混合两个分支所提取的图像特征。使用TransFuse,可以以较浅的方式有效地捕获全局依赖性和low-level空间细节
- transformer:good at modeling global context,but lack of spatial inductive-bias in modelling local information and limitations in capturing fine-grained details
- CNN:low-level spatial details can be efficiently captured but lack of efficiency in capturing global context information
TransFuse在多个医学分割任务中达到SOTA,并在降低参数和提高推理速度方面得到很大的提升。
- advantage:firstly, by leveraging the merits of CNNs and Transformers, we argue that TransFuse can capture global information without building very deep nets while preserving sensitivity on low-level context; secondly, our proposed BiFusion module may simultaneously exploit different characteristics of CNNs and Transformers during feature extraction, thus making the fused representation powerful and compact.
Methods and Creativity
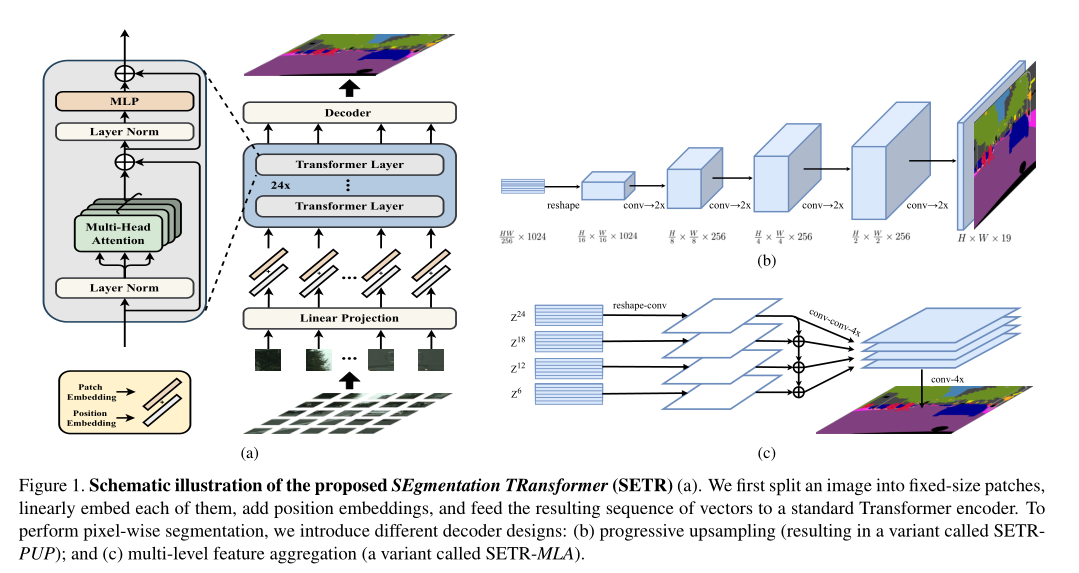
整体网络架构,TransFuse包含两个分支,左边是transformer分支,右边是CNN分支,模型通过BiFusion层整合两个分支的特征,然偶经过上采样和attention-gated skip-connection输出分割结果
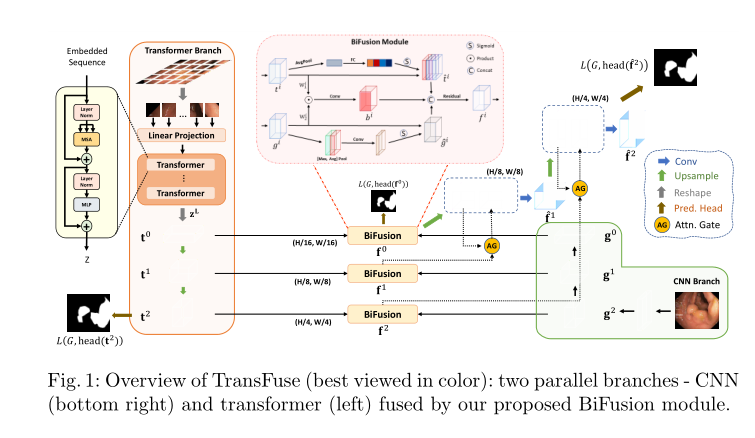
Transformer Branch
Transformer Branch是一个完整的编解码结构,编码器部分使用的是transformer结构,解码器部分使用的是SERT中提到的渐进上采样(PUP)结构。CNN Branch
CNN Branch使用ResNet的第四层,第三层和第二层的输出作为这一分支的输出,由于transformer可以捕获全局的上下文信息,故而CNN Branch并不需要设计的很深 。BiFusion Module
BiFusion Module主要由通道注意力和空间注意力组成,对Transformer Branch做通道注意力,对CNN Branch做空间注意力。然后经过卷积,相乘,拼接,残差操作,实现两个分支的特征融合。通道注意力
特征的每一个通道都代表着一个专门的检测器,因此,通道注意力是关注什么样的特征是有意义的。为了汇总空间特征,作者采用了全局平均池化和最大池化两种方式来分别利用不同的信息。通道注意力聚焦在“什么”是有意义的输入图像
空间注意力
空间注意力模块来关注哪里的特征是有意义的,空间注意力聚焦在“哪里”是最具信息量的部分,这是对通道注意力的补充。为了计算空间注意力,沿着通道轴应用平均池化和最大池操作,然后将它们连接起来生成一个有效的特征描述符
通道注意力和空间注意力详细请看 代表性论文 CBAM: Convolutional Block Attention Module
最后通过上采样和attention-gated skip-connection输出分割结果。
Experiments
本文采用四个数据集进行验证,分别是,Polyp Segmentation,Skin Lesion Segmentation, Hip Segmentation,Prostate Segmentation
定量结果
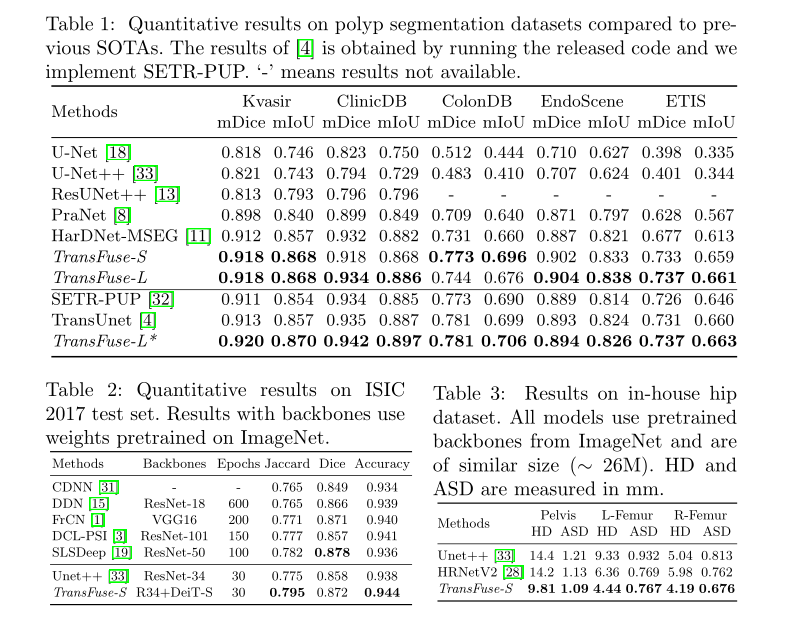
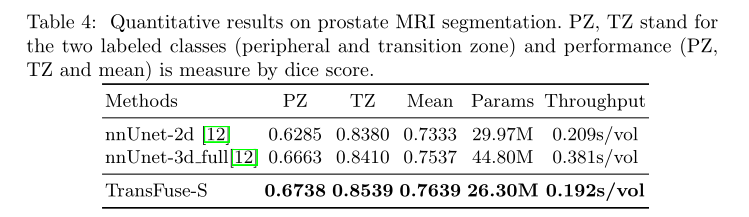
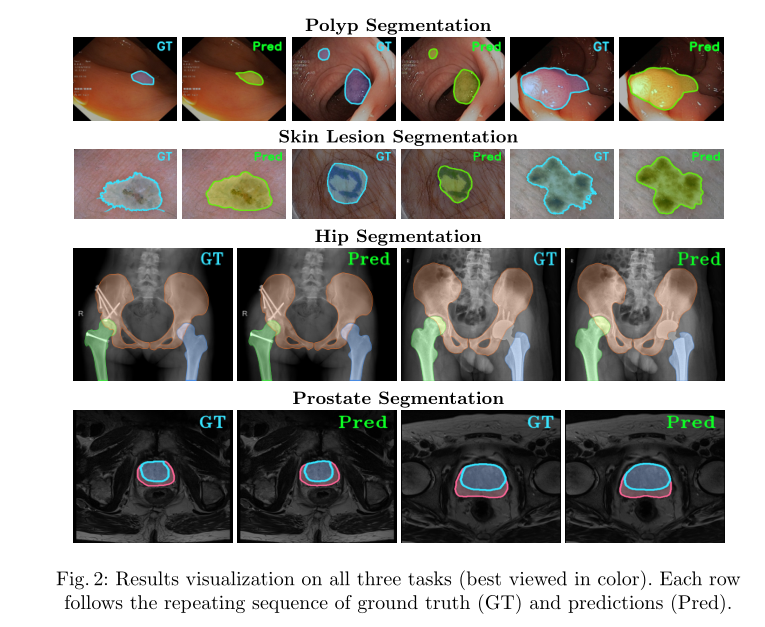
- 可视化结果
- 还有较多的 Ablation experiments,以验证参数选择的有效性。具体的可以查看论文详细内容
Rethingking
文章使用transformer结构捕捉图像的全局上下文信息,并利用这一优点减小CNN结构的层数,只是用很少的卷积层提取局部空间信息作为transformer的补充,并通过BiFusion进行特征融合,最后通过Attention-gate,上采样输出分割结果。文中一共出现四种注意力机制。