浅析UNet
前言
研究一个深度学习算法,可以先看网络结构,看懂网络结构后,再Loss计算方法、训练方法等。本文主要针对UNet的网络结构进行讲解
卷积神经网络被大规模的应用在分类任务中,输出的结果是整个图像的类标签。但是UNet是像素级分类,输出的则是每个像素点的类别,且不同类别的像素会显示不同颜色,UNet常常用在生物医学图像上,而该任务中图片数据往往较少。所以,Ciresan等人训练了一个卷积神经网络,用滑动窗口提供像素的周围区域(patch)作为输入来预测每个像素的类标签。
- 优点
- 输出结果可以定位出目标类别的位置;
- 由于输入的训练数据是patches,这样就相当于进行了数据增强,从而解决了生物医学图像数量少的问题,数据增强有利于模型的训练
- 缺点
- 训练过程较慢,网络必须训练每个patches,由于每个patches具有较多的重叠部分,这样持续训练patches,就会导致相当多的图片特征被多次训练,造成资源的浪费,导致训练时间加长且效率会低下。但是也会认为网络对这个特征进行多次训练,会对这个特征影响十分深刻,从而准确率得到改进。但是这里你拿一张图片复制100次去训练,很可能会出现过拟合的现象,对于这张图片确实十分敏感,但是拿另外一张图片来就可能识别不出了啦
- 定位准确性和获取上下文信息不可兼得,大的patches需要更多的max-pooling,这样会减少定位准确性,因为最大池化会丢失目标像素和周围像素之间的空间关系,而小patches只能看到很小的局部信息,包含的背景信息不够。
网络结构原理
UNet网络结构,最主要的两个特点是:U型网络结构和Skip Connection跳层连接。
UNet网络结构分为三个部分,原理图如下:
第一部分是主干特征提取部分,我们可以利用主干部分获得一个又一个的特征层,Unet的主干特征提取部分与VGG相似,为卷积和最大池化的堆叠。利用主干特征提取部分我们可以获得五个初步有效特征层,在第二步中,我们会利用这五个有效特征层可以进行特征融合。
下采样
左边特征提取网络:使用conv和pooling,就是每次向下采样之前都会进行两次的卷积操作,然后向下采样,然后再进行两次卷积操作,以此往复,向下连续采样五次
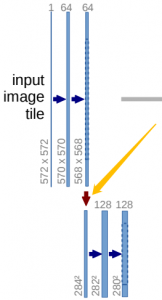
第二部分是加强特征提取部分,我们可以利用主干部分获取到的五个初步有效特征层进行上采样,并且进行特征融合,获得一个最终的,融合了所有特征的有效特征层。
上采样
右边网络为特征融合网络:使用上采样产生的特征图与左侧特征图进行concatenate操作
Skip Connection中间四条灰色的平行线,Skip Connection就是在上采样的过程中,融合下采样过过程中的feature map。Skip Connection用到的融合的操作也很简单,就是将feature map的通道进行叠加,俗称Concat。
Concat操作也很好理解,举个例子:一本大小为10cm10cm,厚度为3cm的书A,和一本大小为10cm10cm,厚度为4cm的书B。将书A和书B,边缘对齐地摞在一起。这样就得到了,大小为10cm*10cm厚度为7cm的一摞书(就是直接把书叠起来的意思)
对于feature map,一个大小为256 256 64的feature map,即feature map的w(宽)为256,h(高)为256,c(通道数)为64。和一个大小为256 256 32的feature map进行Concat融合,就会得到一个大小为256 256 96的feature map。
在实际使用中,Concat融合的两个feature map的大小不一定相同,例如256 256 64的feature map和240 240 32的feature map进行Concat。
这种时候,就有两种办法:
第一种:将大256 256 64的feature map进行裁剪,裁剪为240 240 64的feature map,比如上下左右,各舍弃8 pixel,裁剪后再进行Concat,得到240 240 96的feature map。
第二种:将小240 240 32的feature map进行padding操作,padding为256 256 32的feature map,比如上下左右,各补8 pixel,padding后再进行Concat,得到256 256 96的feature map。
UNet采用的Concat方案就是第二种,将小的feature map进行padding,padding的方式是补0,一种常规的常量填充。
第三部分是预测部分,我们会利用最终获得的最后一个有效特征层对每一个特征点进行分类,相当于对每一个像素点进行分类。(将最后特征层调整通道数,也就是我们要分类个数)
- 最后再经过两次卷积操作,生成特征图,再用两个卷积核大小为1*1的卷积做分类得到最后的两张heatmap,例如第一张表示第一类的得分,第二张表示第二类的得分heatmap,然后作为softmax函数的输入,算出概率比较大的softmax,然后再进行loss,反向传播计算。
网络代码实现
按照UNet的网络结构分parts去实现Unet结构,采取一种搭积木的方式,先定义各个独立的模块,最后组合拼接就可以!
DoubleConv模块
如下图所示模块,连续的两个卷积的操作,在整个UNet网络中,主干特征提取网络和加强特征网络中各自使用了五次,每一层都会采取这个操作,故可以提取出来:
1 | class DoubleConv(nn.Module): |
nn.Sequential 是一个时许的容器,会将里面的 modle 逐一执行,执行顺序为:卷积->BN->ReLU->卷积->BN->ReLU。
in_channels, out_channels,输入输出通道定义为参数,增强扩展使用
卷积 nn.Conv2d 的输出:
nn. Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0,dilation=1, groups=1, bias=True, padding_mode= ‘zeros’ )
- in_channels:输入的四维张量[N, C, H, W]中的C,也就是说输入张量的channels数。这个形参是确定权重等可学习参数的shape所必需的。
- out_channels:也很好理解,即期望的四维输出张量的channels数,不再多说。
- kernel_size:卷积核的大小,一般我们会使用5x5、3x3这种左右两个数相同的卷积核,因此这种情况只需要写kernel_size = 5这样的就行了。如果左右两个数不同,比如3x5的卷积核,那么写作kernel_size = (3, 5),注意需要写一个tuple,而不能写一个列表(list)。
stride = 1:卷积核在图像窗口上每次平移的间隔,即所谓的步长。这个概念和Tensorflow等其他框架没什么区别,不再多言。 - padding:这是Pytorch与Tensorflow在卷积层实现上最大的差别,padding也就是指图像填充,后面的int型常数代表填充的多少(行数、列数),默认为0。需要注意的是这里的填充包括图像的上下左右,以padding=1为例,若原始图像大小为32 32,那么padding后的图像大小就变成了34 34,而不是33*33。
Pytorch不同于Tensorflow的地方在于,Tensorflow提供的是padding的模式,比如same、valid,且不同模式对应了不同的输出图像尺寸计算公式。而Pytorch则需要手动输入padding的数量,当然,Pytorch这种实现好处就在于输出图像尺寸计算公式是唯一的, - dilation:这个参数决定了是否采用空洞卷积,默认为1(不采用)。从中文上来讲,这个参数的意义从卷积核上的一个参数到另一个参数需要走过的距离,那当然默认是1了,毕竟不可能两个不同的参数占同一个地方吧(为0)。更形象和直观的图示可以观察Github上的Dilated convolution animations,展示了dilation=2的情况。
- groups:决定了是否采用分组卷积,groups参数可以参考groups参数详解
- bias:即是否要添加偏置参数作为可学习参数的一个,默认为True。
- padding_mode:即padding的模式,默认采用零填充。
输出通道就是 out_channels
输出的 X * X 计算公式:
- I 为输入feature map的大小,O为输出feature map的大小,K为卷积核的大小,P为padding的大小,S为步长
Down(下采样模块)
UNet的下采样模块有着4次的下采样过程,过程如下
1 | class Down(nn.Module): |
- 代码很简单,就是一个maxpool池化层,进行下采样,然后接一个DoubleConv模块。
- 到这里,左边的网络完成!!
Up(上采样模块)
上采样模块就是出来常规的上采样操作以外,还需要进行特征融合,
1 | class Up(nn.Module): |
初始化函数里定义的上采样方法(反卷积)以及卷积采用DoubleConv
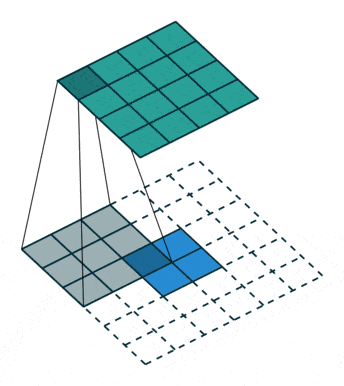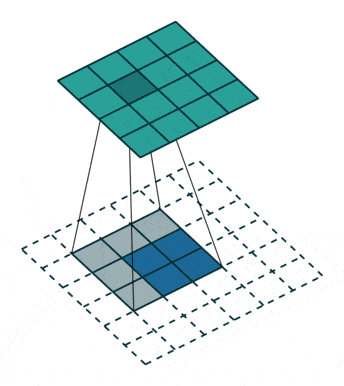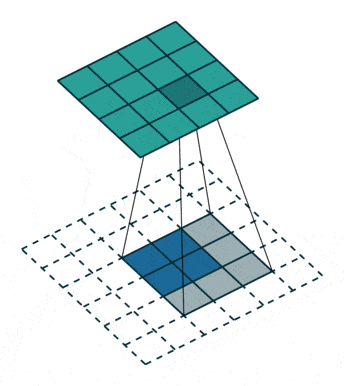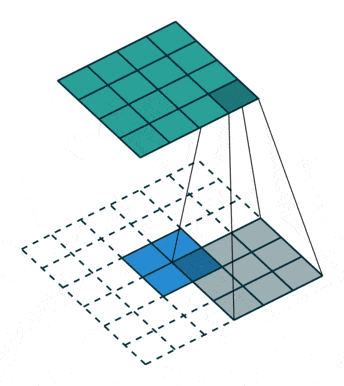
反卷积,顾名思义,就是反着卷积。卷积是让featuer map越来越小,反卷积就是让feature map越来越大,
下面蓝色为原始图片,周围白色的虚线方块为padding结果,通常为0,上面绿色为卷积后的图片。
这个示意图,就是一个从 2 * 2的feature map —-> 4 * 4 的feature map过程。
在forward前向传播函数中,x1接收的是上采样的数据,x2接收的是特征融合的数据。特征融合方法就是,上文提到的,先对小的feature map进行padding,再进行concat。
OutConv模块
用上述的DoubleConv模块、Down模块、Up模块就可以拼出UNet的主体网络结构了。UNet网络的输出需要根据分割数量,整合输出通道。
利用前面的模块,我们可以获取输入进来的图片的特征,此时,我们需要利用特征获得预测结果
利用特征获得预测结果的过程为:
- 利用一个1x1卷积进行通道调整,将最终特征层的通道数调整成num_classes。 (即对每一个像素点进行分类)
这个过程简单,顺便也包装一下吧
1 | class OutConv(nn.Module): |
到这里,所有的积木已经完成了,接下来就是搭建的过程了。
UNet模块
到这里,按照UNet网络结构,设置每个模块的输入输出通道个数以及调用顺序,代码如下:
1 | import torch.nn.functional as F |
训练网络
训练网络的代码:
1 | import os |
封装数据集的办法主要采用:自定义类继承Dataset,下面展示的是他的伪代码:
1 | # ================================================================== # |
- init函数是这个类的初始化函数,根据指定的图片路径,读取所有图片数据,
- len函数可以返回数据的多少,这个类实例化后,通过len()函数调用。
- getitem函数是数据获取函数,在这个函数里你可以写数据怎么读,怎么处理,并且可以一些数据预处理、数据增强都可以在这里进行
下面的是自定义的这个方法:
1 | class DeeplabDataset(Dataset): |
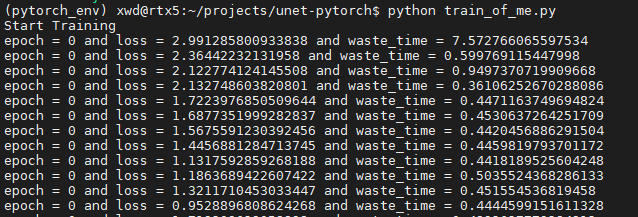
我这边设置的epoch并不算很大,采用3090的显卡也是运行了一段时间是时间,可以看到网络,loss实在逐渐在收敛的:
采用训练好的模型进行预测,看看结果如何:
这边采用的是在网络上copy的图片预处理和后续处理的代码,本人目前对图片处理还是比较菜,把别人的代码贴在这里,最后给出自己的预测结果:
1 | import colorsys |
调用这个函数,得到的预测结果如下:


语义分割的MIOU指标
语义分割的标准度量。其计算所有类别交集和并集之比的平均值.,语义分割说到底也还是一个分割任务,既然是一个分割的任务,预测的结果往往就是四种情况:
true positive(TP):预测正确, 预测结果是正类, 真实是正类
false positive(FP):预测错误, 预测结果是正类, 真实是负类
true negative(TN):预测错误, 预测结果是负类, 真实是正类
false negative(FN):预测正确, 预测结果是负类, 真实是负类
mIOU 的定义:计算真实值和预测值两个集合的交集和并集之比。这个比例可以变形为TP(交集)比上TP、FP、FN之和(并集)。即:mIOU=TP/(FP+FN+TP)。
计算公式:
等价于:
mIOU一般都是基于类进行计算的,将每一类的IOU计算之后累加,再进行平均,得到的就是基于全局的评价。
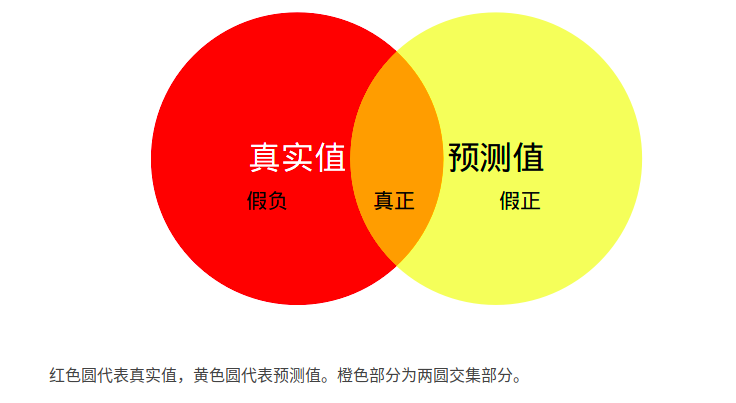
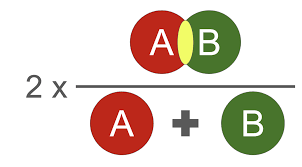
MIoU:计算两圆交集(橙色部分)与两圆并集(红色+橙色+黄色)之间的比例,理想情况下两圆重合,比例为1。
计算本网络的MIoU可以采样训练好的模型进行计算,计算的结果比例越接近1效果越好。
代码实现后续把,hhhhhhhhhhhhhhhhhhhhh。。。。。。。